ToRA: 革命性的工具集成推理智能体
ToRA: 开启数学推理新纪元的智能体
在人工智能快速发展的今天,解决复杂数学问题仍然是一个巨大的挑战。微软研究院最近推出的ToRA(Tool-integrated Reasoning Agent)系列模型,为这一领域带来了革命性的突破。ToRA不仅融合了自然语言处理的强大能力,还巧妙地集成了外部工具的使用,为解决数学推理问题开辟了一条崭新的道路。
ToRA的核心理念
ToRA的核心理念是将语言模型的推理能力与外部工具的计算效率无缝结合。这种创新的方法使得ToRA能够在处理复杂数学问题时,既能利用语言模型的灵活性进行推理,又能借助外部工具进行精确计算。

这种工具集成推理的方法不仅提高了问题解决的准确性,还大大扩展了模型的应用范围。ToRA能够处理从简单的算术问题到复杂的代数、几何甚至是高等数学问题,展现出了惊人的versatility。
ToRA的训练流程
ToRA的训练过程是一个精心设计的多阶段流程,主要包括两个关键步骤:
模仿学习(Imitation Learning):在这个阶段,ToRA学习如何模仿人类专家解决数学问题的方法。这包括理解问题、制定解决策略、以及如何恰当地使用外部工具。
输出空间塑造(Output Space Shaping):这个阶段旨在优化模型的输出质量。通过精心设计的训练数据和目标,ToRA学会了如何生成更加精确、结构化的解答。
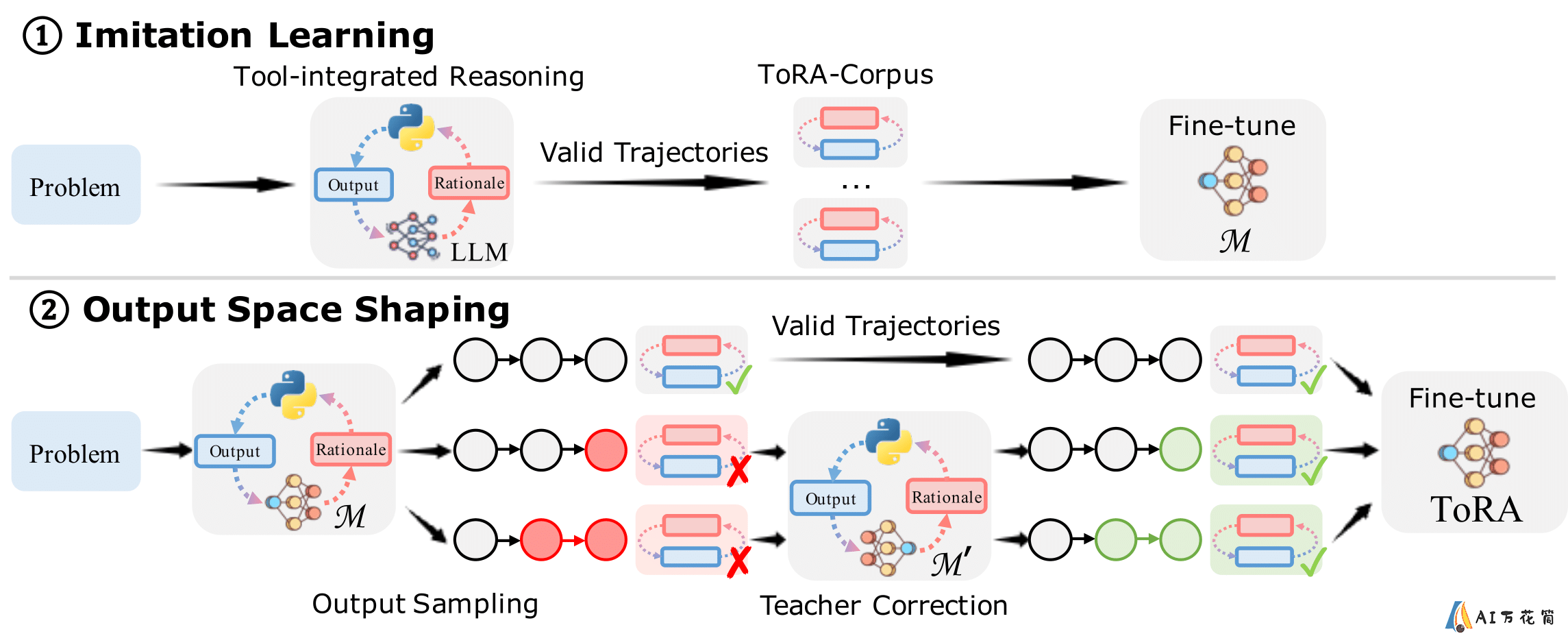
这种训练方法使得ToRA不仅能够给出正确的答案,还能提供清晰、逻辑严密的解题过程,这对于教育和研究领域都具有重要意义。
ToRA的性能表现
ToRA系列模型在多个benchmark上展现出了卓越的性能,特别是在GSM8k和MATH这两个著名的数学推理数据集上。
GSM8k:ToRA-70B模型在这个数据集上达到了84.3%的准确率,使用自洽性(self-consistency)技术后,准确率更是提升到了88.3%。MATH:ToRA-Code-34B模型在MATH数据集上取得了51.0%的准确率,这是首个在该数据集上超过50%准确率的开源模型。使用自洽性技术后,准确率进一步提升至60.0%。这些结果不仅超越了许多现有的开源模型,甚至在某些任务上接近或超过了GPT-4的表现。
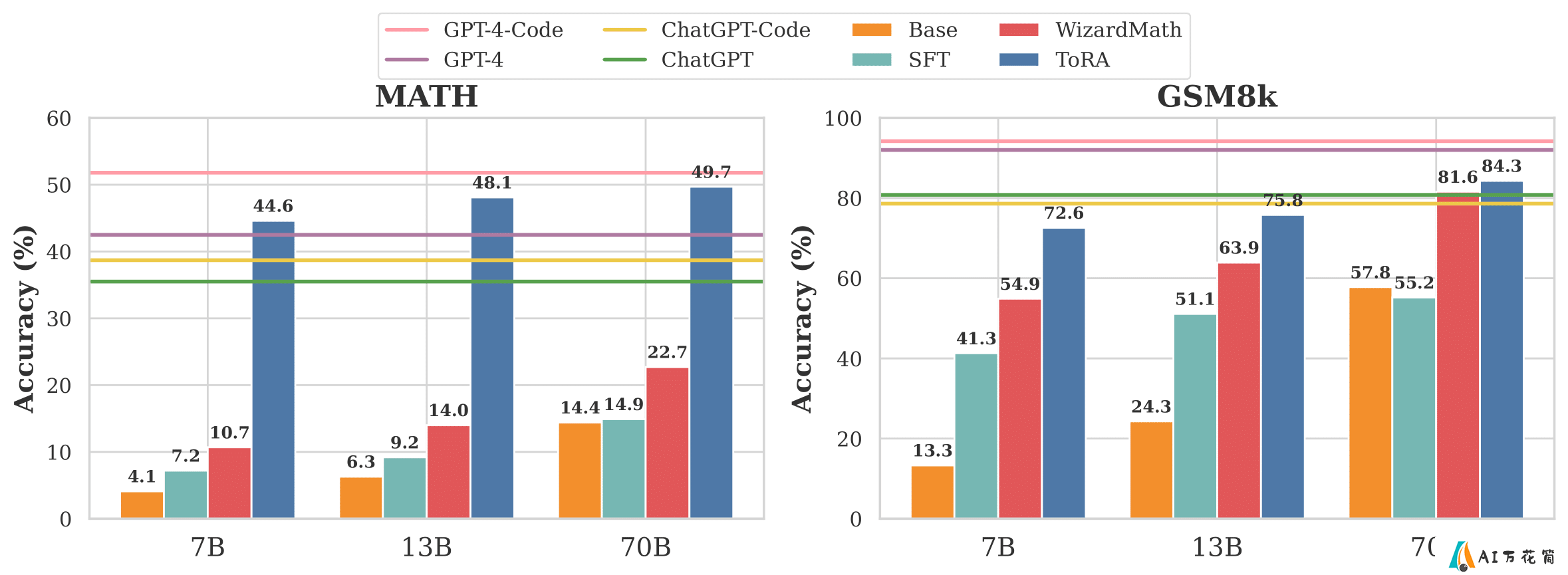
ToRA的工具集成推理示例
为了更好地理解ToRA如何工作,让我们看一个简单的例子:
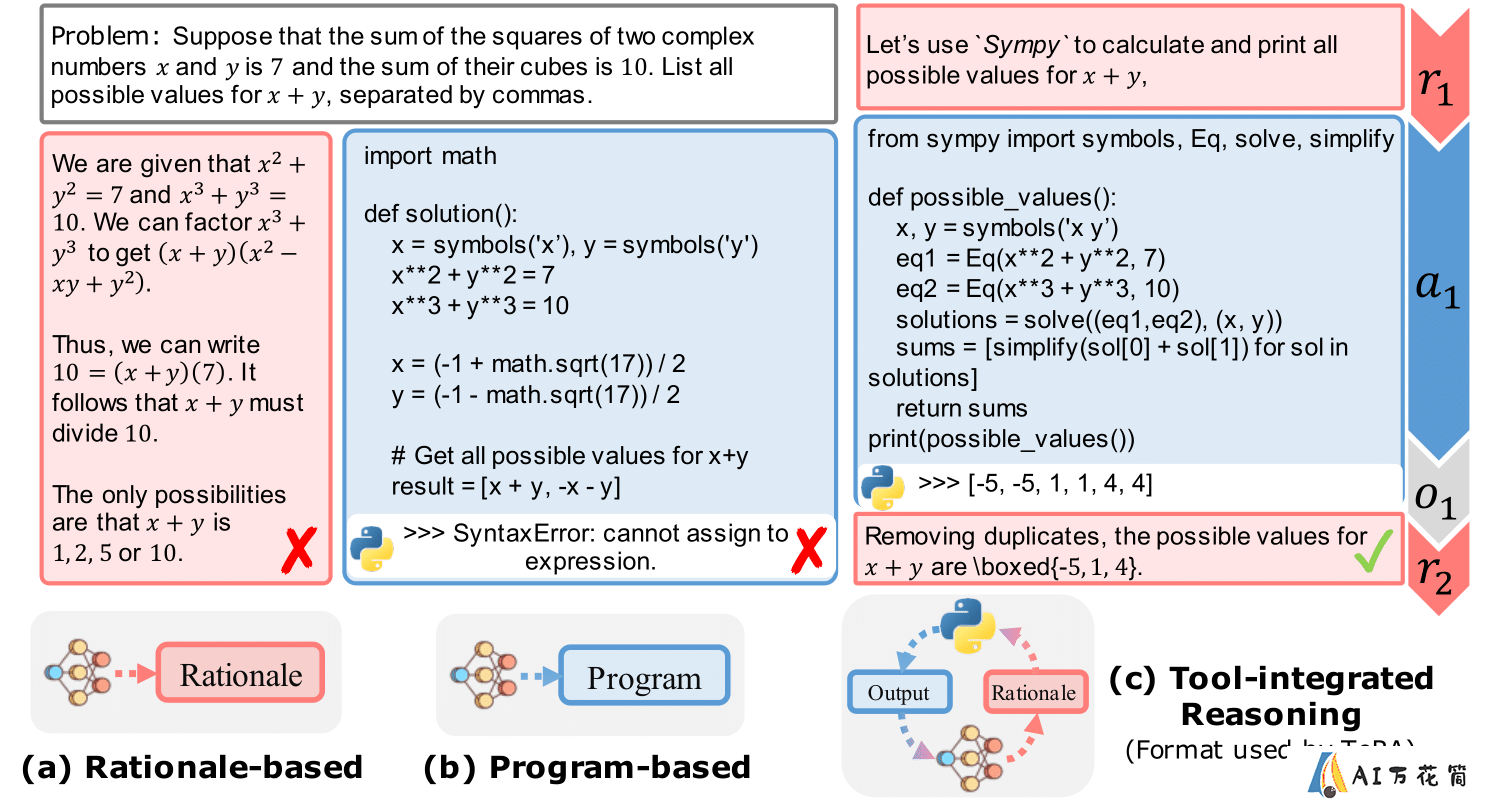
在这个例子中,我们可以清楚地看到ToRA是如何将自然语言推理与工具使用相结合的。模型首先分析问题,然后决定使用适当的工具(在这里是一个计算库)来进行必要的计算。这种方法不仅提高了解答的准确性,还使得整个解题过程更加透明和可解释。
ToRA的开源贡献
微软研究院不仅公开了ToRA的研究成果,还在GitHub上开源了相关代码和模型。这一举措大大促进了社区的参与和进一步的研究。研究者和开发者可以通过以下方式使用ToRA:
模型下载:所有ToRA模型都可以在-
下一篇: 最后一页
- ToRA: 革命性的工具集成推理智能体
- Index-1.9B: 哔哩哔哩自主研发的轻量级多语言大模型
- 小鱼AI写作:重写违禁词,自动检测和修改敏感词!
- GenossGPT:开源AI模型的统一接口
- CodeFuse-ChatBot: 革新软件开发生命周期的AI智能助手
- 【易米AI 3.1】版本升级!集成GPT-4、Claude2.1等大模型,功能体验升级,速来尝新!
- Ocular: 革新企业搜索与生成式AI的开源平台
- Continuous-Eval: 数据驱动的LLM应用评估框架
- Smart Second Brain: 让您的第二大脑更智能的Obsidian插件
- AiPPT入驻文心一言插件商城,开启“便携办公”新形态!
-

TxAgent:用于治疗推理和个性化药物治疗方案制定的AI智能体
2025-05-02
-

Stability AI发布Stable Code 3B模型
2025-05-05
-

2025-05-01
-

2025-05-04
-
2025-05-07
-

2025-05-02
-

2025-05-05
-

-

2025-05-04
-

Chinese-LLaMA-Alpaca: 开源中文大语言模型的突破性进展
2025-05-07









