MetaVoice-1B: 开源人性化表情丰富的文本转语音基础模型
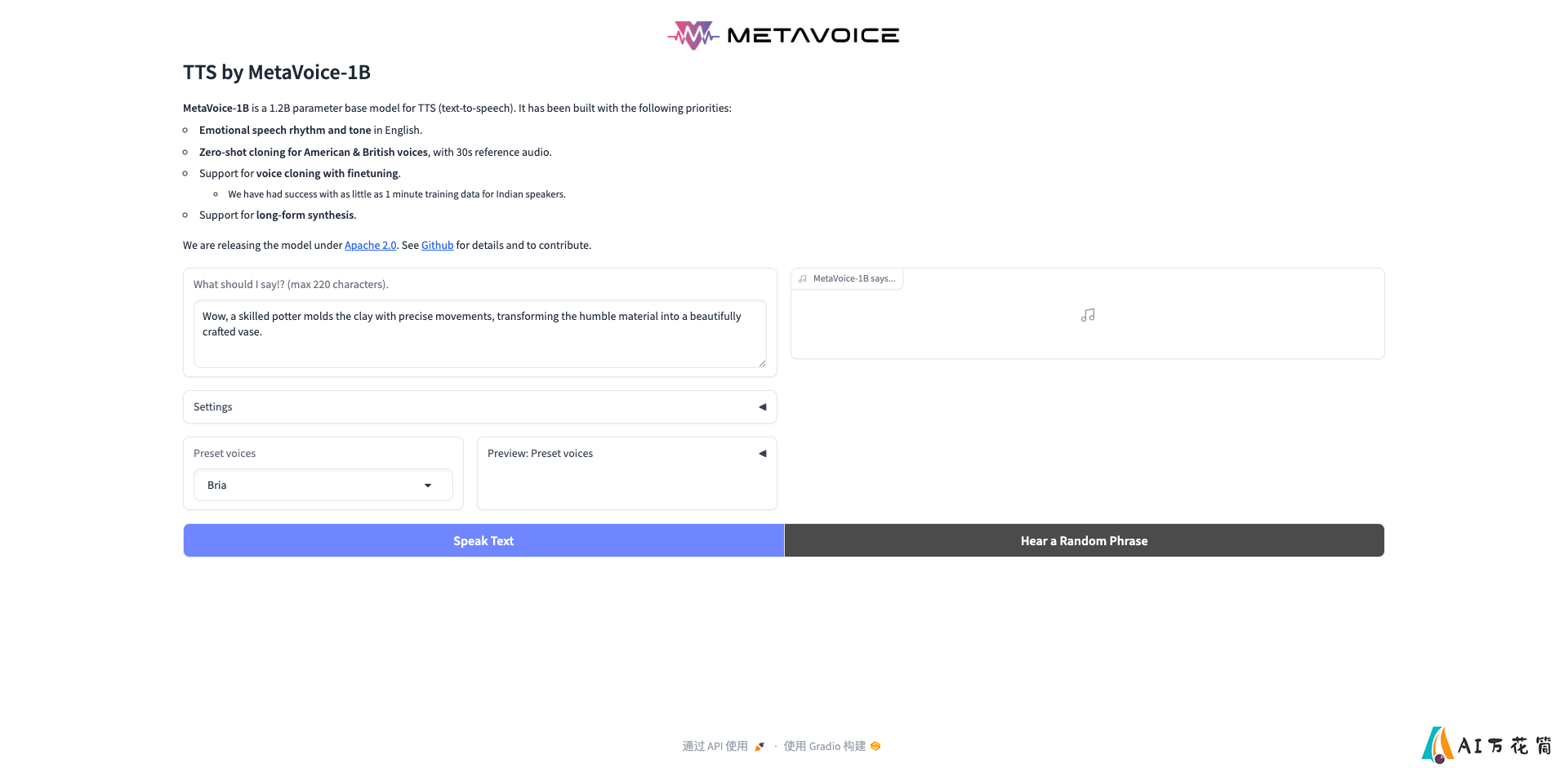
MetaVoice-1B:开启人性化语音合成新纪元
在人工智能快速发展的今天,语音合成技术正在以惊人的速度进步。MetaVoice-1B作为一个开源的文本转语音(TTS)基础模型,正在为这一领域带来革命性的变化。本文将深入探讨MetaVoice-1B的特点、应用场景以及它对TTS技术发展的重要意义。
MetaVoice-1B的核心特点
MetaVoice-1B是一个拥有12亿参数的基础模型,经过了10万小时语音数据的训练。它的设计理念主要围绕以下几个方面:
情感丰富的语音节奏和语调:MetaVoice-1B能够生成富有情感和表现力的英语语音,使合成的语音更加自然、生动。
零样本声音克隆:只需30秒的参考音频,MetaVoice-1B就能实现美式和英式口音的零样本声音克隆,大大提高了模型的灵活性和适用性。
跨语言声音克隆:通过微调,MetaVoice-1B支持跨语言的声音克隆。实践表明,对于印度语音者,仅需1分钟的训练数据就能取得不错的效果。
长文本合成:MetaVoice-1B能够合成任意长度的文本,满足各种应用场景的需求。
开源免费:MetaVoice-1B采用Apache 2.0许可证发布,可以无限制地使用,这为TTS技术的研究和应用提供了宝贵的资源。
MetaVoice-1B的应用场景
MetaVoice-1B的强大功能为多个领域带来了新的可能性:
个性化语音助手:利用声音克隆技术,可以为用户创建独特的语音助手,提供更加个性化的交互体验。
有声读物制作:MetaVoice-1B可以快速生成富有情感的语音内容,大大提高有声读物的制作效率。
视频配音:通过声音克隆,可以轻松实现跨语言的视频配音,使内容更容易在全球范围内传播。
语音合成API:开发者可以基于MetaVoice-1B构建强大的语音合成API,为各种应用提供高质量的TTS服务。
教育培训:在语言学习和发音训练中,MetaVoice-1B可以提供多样化的语音示例,帮助学习者提高听说能力。
使用MetaVoice-1B
MetaVoice-1B提供了多种使用方式,以满足不同用户的需求:
本地部署:用户可以下载模型并在本地环境中使用,通过提供的参考实现快速开始。# 示例代码tts.synthesise(text="This is a demo of text to speech by MetaVoice-1B, an open-source foundational audio model.", spk_ref_path="assets/bria.mp3")云端部署:MetaVoice-1B可以部署在各种云平台(AWS/GCP/Azure)上,通过推理服务器或Web UI提供服务。
Hugging Face集成:用户可以直接通过Hugging Face使用MetaVoice-1B。
Google Colab:提供了Google Colab演示,方便用户快速体验和测试。
MetaVoice-1B的技术架构
MetaVoice-1B采用了先进的多阶段架构设计:
第一阶段:使用因果GPT预测EnCodec令牌的前两个层次。文本和音频作为LLM上下文的一部分,而说话人信息通过令牌嵌入层的条件传递。
第二阶段:使用非因果(编码器风格)Transformer从前两个层次预测剩余的6个层次。这是一个非常小的模型(约1000万参数),但对大多数说话人都有广泛的零样本泛化能力。
波形生成:使用多频带扩散从EnCodec令牌生成波形。这种方法比原始RVQ解码器或VOCOS产生更清晰的语音。
后处理:使用DeepFilterNet清除多频带扩散引入的背景伪音。
性能优化
MetaVoice-1B在性能方面也做了多项优化:
KV缓存:通过Flash Decoding实现KV缓存,提高推理速度。
批处理支持:支持不同长度文本的批处理,提高处理效率。
量化:提供int4和int8量化模式,在一定程度上牺牲音质的情况下,可以显著提高推理速度。
MetaVoice-1B的未来发展
MetaVoice-1B团队已经公布了未来的发展计划:
更快的推理速度:继续优化模型,提供更快的推理性能。
微调代码:发布微调代码,使用户能够根据自己的需求定制模型。
任意长度文本合成:进一步改进长文本合成能力,实现真正的任意长度文本合成。
结语
MetaVoice-1B作为一个开源的TTS基础模型,不仅为研究人员和开发者提供了宝贵的资源,也为语音合成技术的发展注入了新的活力。它的开放性和强大功能,将推动TTS技术在各个领域的应用,为人机交互带来更自然、更人性化的体验。
随着MetaVoice-1B的不断发展和完善,我们可以期待看到更多创新的语音应用出现,为我们的日常生活和工作带来更多便利和乐趣。无论是个人用户、企业还是研究机构,都可以从这个强大的开源项目中受益,共同推动语音技术的进步。
让我们一起期待MetaVoice-1B在未来带来的更多惊喜和突破!
-
上一篇: ADeus: 开源AI可穿戴设备的未来
-
下一篇: 最后一页
-
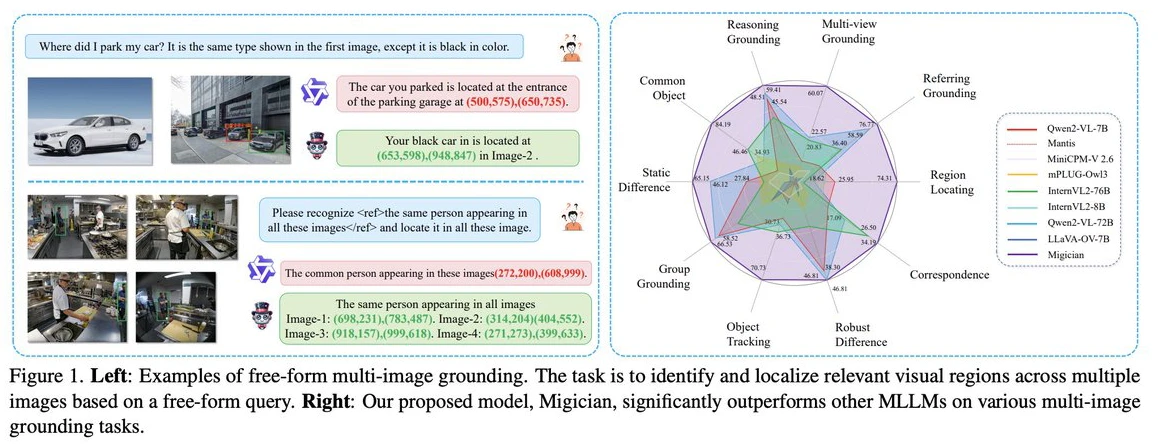
Migician:清华大学等团队出的解决复杂场景下的多图像目标定位问题的多模态模型
2025-03-11
-

MILS:Meta发布的无需训练就能让LLM获得多模态能力的方法
2025-03-28
-

2025-04-14
-

Gemini 2.5 Pro与Gemini 2.5相比较,有哪些提升?
2025-04-29
-
2025-02-24
-
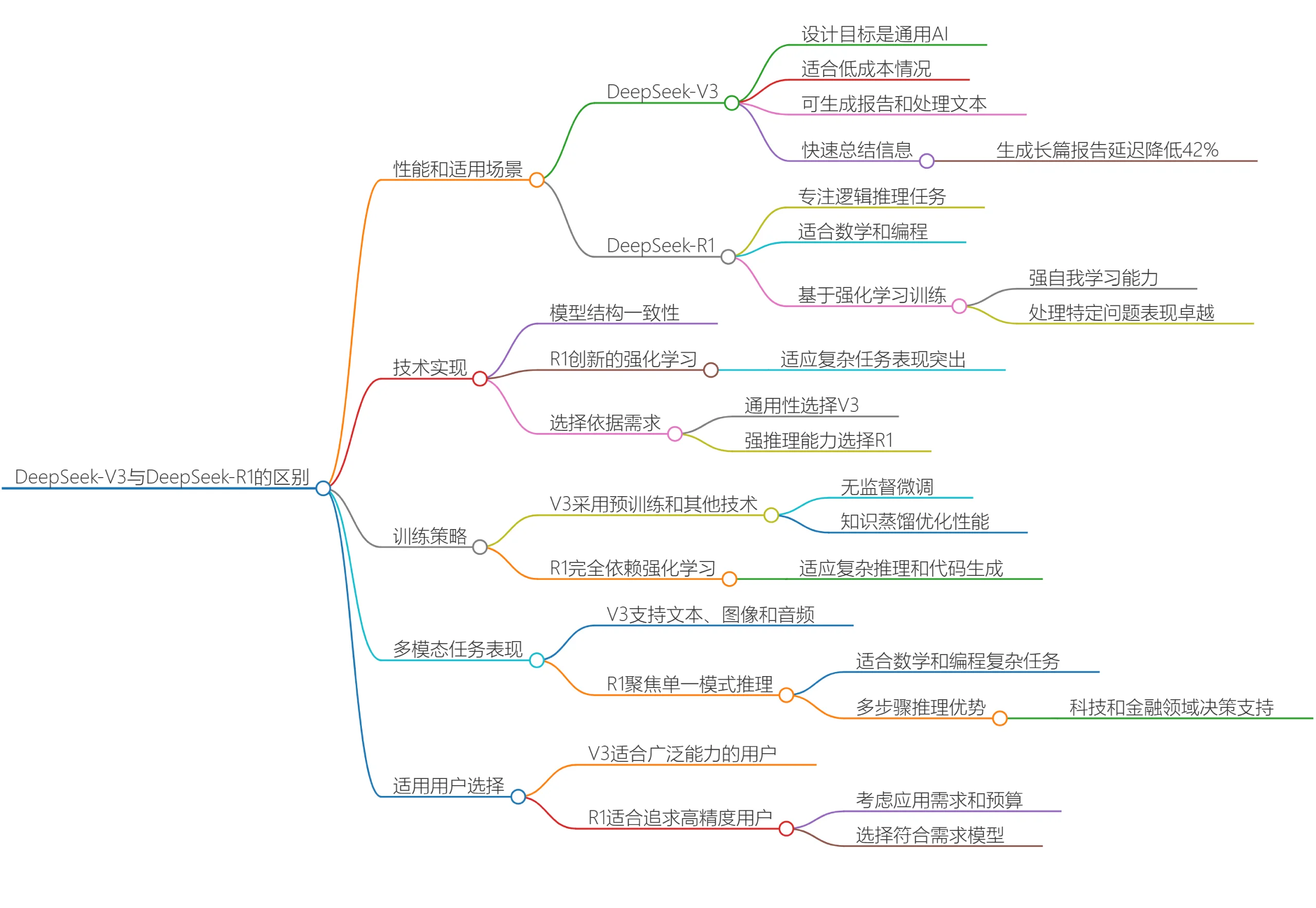
DeepSeek V3和DeepSeek R1有什么区别?哪个更适合你呢?
2025-03-20
-

2025-04-05
-

2025-04-21
-
文生图模型Ideogram 2A:更快的生成速度和更低的成本
2025-03-12
-
2025-03-28








