No-OCR:一款不需要OCR文本提取的文档处理工具
No-OCR是什么?
No-OCR是一款不需要复杂OCR文本提取的文档处理工具,只需上传PDF文件,就可以快速搜索或查询多个文档集合中的内容,不需要依赖传统OCR技术,可以提升文档分析效率。它支持创建和管理PDF/文档集合,并按“案例”分类组织,同时自动构建Hugging Face风格的数据集。此外,No-OCR还具备基于向量的PDF页面和相关图像搜索功能(使用LanceDB),并通过Qwen2-VL实现图像和图表的视觉问答。它支持文本和视觉查询的混合搜索,可通过Docker快速部署,配置简单,还提供了详细的开发安装说明。

No-OCR特点
无需OCR:完全不依赖OCR技术,适用于视觉内容丰富的PDF文件。
简单易用:上传PDF文件后即可进行搜索,支持复杂视觉内容(如表格、图表、布局等)。
开源模型:基于开源的LLM(大型语言模型)进行内容检索和解释。
可部署性:支持Docker部署,适用于任何企业环境。
No-OCR使用场景
适用场景:如果文档包含丰富的视觉内容(如表格、图表、布局等),No-OCR是一个很好的选择。
不适用场景:如果文档主要是纯文本内容,传统的BM25搜索可能更适合。
混合内容:如果文档包含文本和视觉内容的混合,可能需要根据需求调整解决方案。
No-OCR架构设计
简单架构:不依赖数据库或消息队列,所有持久化操作均基于文件系统。
主要服务:
Modal:用于LLM的部署。
Qdrant:用于多向量搜索。
Supabase:用于用户认证和授权。
创建案例:用户上传PDF文件并指定案例名称,系统会将PDF转换为数据集并上传到Qdrant。
搜索流程:用户输入搜索查询,系统通过LLM识别相关页面并解释内容。
No-OCR LLM模型
ColPali家族:用于图像检索,将图像转换为可搜索格式。
Qwen2-VL家族:用于视觉内容的推理,特别是Qwen2-VL-7B-Instruct模型,是目前最先进的开源视觉模型之一。

创建案例流程
工作原理
No-OCR平台采用简化的RAG方法,用户只需上传PDF文件创建案例,系统会处理这些文件并使其可搜索。用户可以提出任何问题,包括关于视觉元素的问题,平台会利用顶级开源推理模型提供答案。

搜索流程
No-OCR使用步骤
上传并处理复杂PDF:用户上传具有挑战性的PDF文件创建新案例,系统会生成嵌入,无需复杂的OCR处理。
使其可搜索:处理完成后,用户可以运行基于文本的查询,快速找到相关页面和引用,无论PDF布局多么复杂。
提出视觉相关问题:平台会快速定位相关页面,然后通过专门的开源视觉模型进一步提炼答案,即使PDF包含图表或图表,也能提供上下文感知的见解。
TLDR:https://no-ocr.com/about
Github:https://github.com/kyryl-opens-ml/no-ocr
-
上一篇: 桃豆:爱奇艺发布的个人智能助手
-
下一篇: 最后一页
-
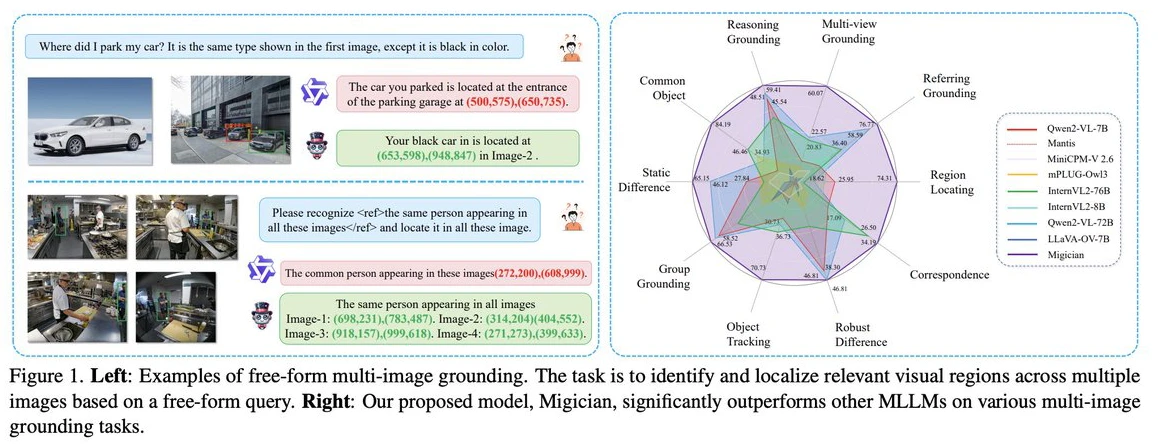
Migician:清华大学等团队出的解决复杂场景下的多图像目标定位问题的多模态模型
2025-03-11
-

MILS:Meta发布的无需训练就能让LLM获得多模态能力的方法
2025-03-28
-

2025-04-14
-

Gemini 2.5 Pro与Gemini 2.5相比较,有哪些提升?
2025-04-29
-
2025-02-24
-
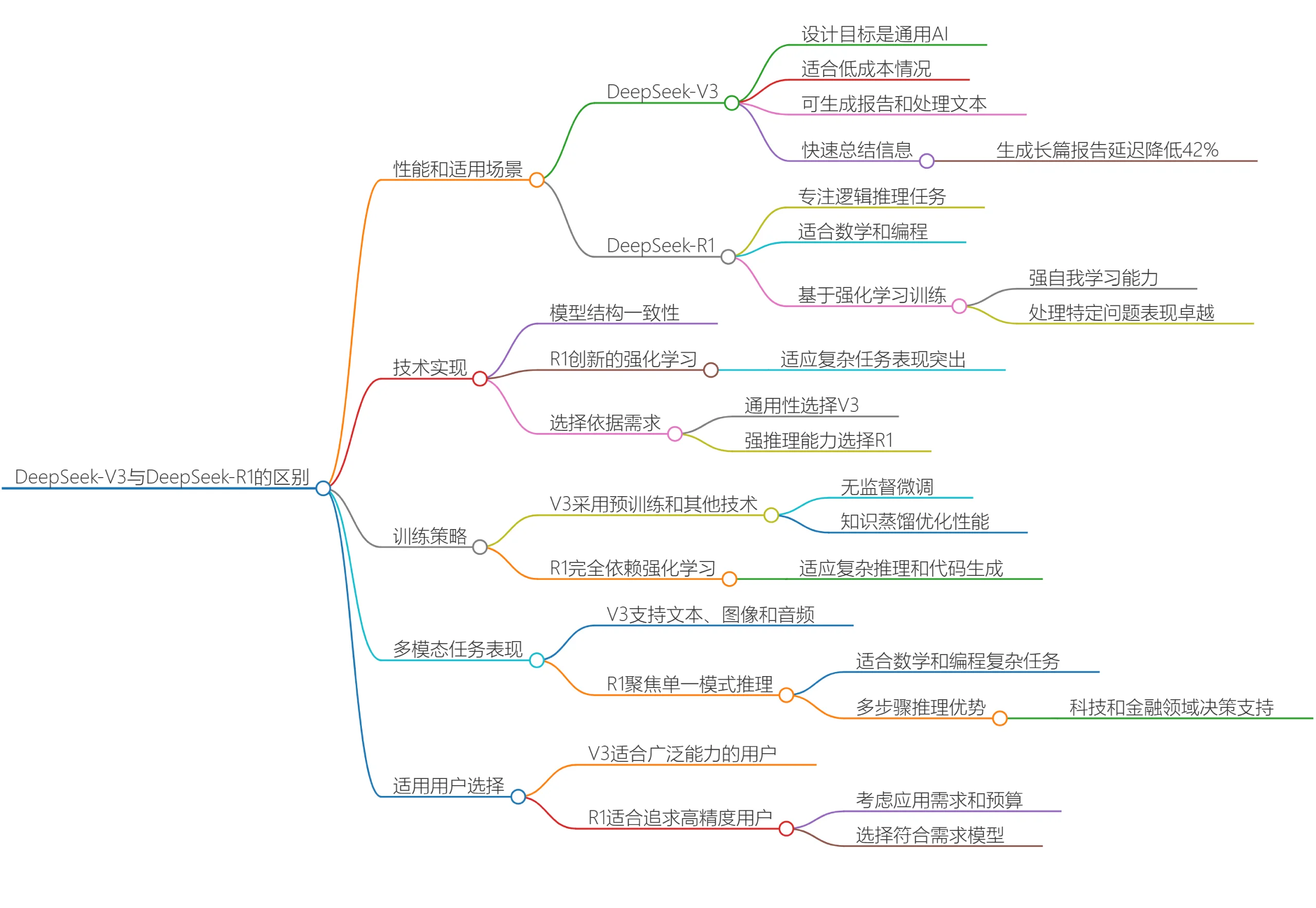
DeepSeek V3和DeepSeek R1有什么区别?哪个更适合你呢?
2025-03-20
-

2025-04-05
-

2025-04-21
-
文生图模型Ideogram 2A:更快的生成速度和更低的成本
2025-03-12
-
2025-03-28








