LLM蒸馏技术全解析:如何用更少的资源获得更强大的小模型
LLM蒸馏技术全解析:如何用更少的资源获得更强大的小模型
近年来,大型语言模型(LLM)在自然语言处理领域取得了巨大突破。然而,这些庞大的模型往往需要大量计算资源才能部署和使用,这限制了它们在实际应用中的普及。为了解决这一问题,模型蒸馏技术应运而生。本文将深入探讨LLM蒸馏的最佳实践,帮助读者掌握如何用更少的资源获得更强大的小模型。
什么是LLM蒸馏?
LLM蒸馏是一种将大型语言模型(教师模型)的知识转移到更小的模型(学生模型)中的技术。通过这种方式,我们可以得到一个更小、更快,同时又保持相当性能的模型。

蒸馏过程通常包括以下步骤:
选择一个强大的教师模型准备高质量的训练数据使用教师模型生成标签数据训练更小的学生模型以模仿教师模型的输出评估和优化学生模型为什么需要LLM蒸馏"/>5. 优化训练数据质量
高质量的训练数据对于成功的蒸馏至关重要。以下是一些提升数据质量的方法:
手动清理和标注数据使用规则过滤低质量数据利用辅助系统(如其他模型)对数据进行排序丰富数据,添加解释或推理过程整合多个教师模型的输出6. 构建多样化和平衡的数据集
训练数据应该覆盖各种场景和复杂度,以提高学生模型的泛化能力。同时,我们还需要注意数据的平衡性,避免某些类别或情况在数据集中过度或不足表示。
如果发现数据分布不均衡,可以采取以下措施:
对稀有样本进行过采样或数据增强对常见样本进行欠采样调整不同样本的权重7. 从简单小型模型开始
在进行大规模实验之前,先从最简单和最小的模型配置开始。这样可以快速迭代和调试,为后续更复杂的模型配置建立基准。
小型模型的优势:
训练速度快,便于快速实验更容易理解和调试为更复杂的模型提供可靠的基准8. 评估更多数据的边际效用
通过进行数据规模消融实验,我们可以了解增加训练数据对模型性能的影响。这有助于我们确定最佳的数据集大小,避免过度收集数据。
例如,我们可以尝试使用不同比例(如10%、25%、50%、75%、100%)的训练数据,观察模型性能的变化趋势。如果发现增加数据后性能提升不明显,那么我们可能需要关注其他方面的优化。
9. 考虑学生模型的部署方式
在设计学生模型时,我们需要考虑其最终的部署方式。不同的部署场景可能对模型大小、推理速度等有不同的要求。
例如,如果需要部署多个专用模型,可以考虑使用参数高效微调(PEFT)技术,如LoRA(Low-Rank Adaptation)。这样可以在保持性能的同时,大幅减少每个模型的参数量。

10. 广泛实验,每次改变一个参数
在进行实验时,我们应该遵循以下原则:
保持实验的组织性,使用模型仓库或电子表格记录实验结果并行运行多个实验,但每次只改变一个参数从简单到复杂,从小到大逐步优化接受一定程度的试错和猜测一些值得尝试的实验方向:
类别参数对质量的影响对速度的影响复杂度架构参数基础模型★★★★★★★★架构参数精度和量化★★★★★★★★★★架构参数适配器参数(rank和alpha)★★★★★★★★★训练参数学习率和学习率调度★★★★★★★训练参数批次大小★★★★★★★★★训练策略课程学习★★★★★★★★★★★★11. 分析模型的具体错误
除了关注整体性能指标,我们还应该深入分析模型在具体样本上的表现。这可以帮助我们:
识别模型的系统性错误发现数据集中的问题找到改进的方向一些分析方法:
随机抽样审核模型输出重点关注模型表现最差的样本比较学生模型和教师模型的输出差异12. 在生产环境中部署和监控模型
最后,我们需要将模型部署到实际生产环境中,并持续监控其性能。这可以帮助我们:
验证模型在真实场景中的表现及时发现和解决潜在问题收集新的数据用于进一步改进模型一些部署和监控的最佳实践:
使用蓝绿部署或金丝雀发布等策略设置关键性能指标(KPI)的监控和报警定期进行A/B测试,比较新旧模型的性能建立用户反馈机制,收集定性评价结语
LLM蒸馏是一项强大的技术,可以让我们以更低的成本获得高性能的小型语言模型。通过遵循本文介绍的最佳实践,我们可以更有效地进行LLM蒸馏,打造出适合特定应用场景的优秀模型。
然而,LLM蒸馏仍然是一个快速发展的领域。我们需要持续关注最新的研究进展,并在实践中不断总结经验。相信随着技术的进步,我们将能够构建出更加高效、强大的语言模型,为各行各业带来更多创新应用。
参考资源
LLM Distillation Playbook: https://github.com/predibase/llm_distillation_playbookDistilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes: https://arxiv.org/abs/2305.02301The False Promise of Imitating Proprietary LLMs: https://arxiv.org/abs/2305.15717LoRA: Low-Rank Adaptation of Large Language Models: https://arxiv.org/abs/2106.09685希望这篇文章能为您的LLM蒸馏之旅提供有价值的指导。如果您有任何问题或想法,欢迎在评论区留言讨论!
-
下一篇: 最后一页
-
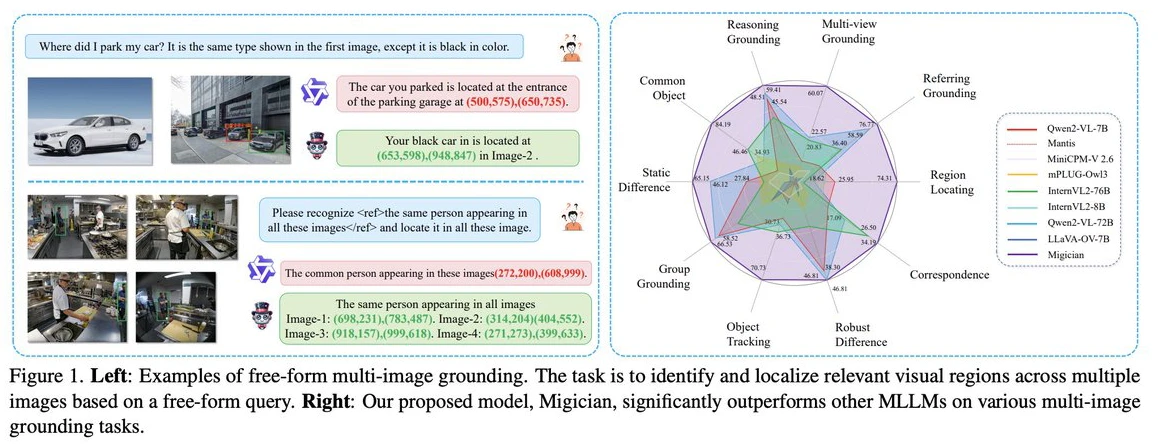
Migician:清华大学等团队出的解决复杂场景下的多图像目标定位问题的多模态模型
2025-03-11
-

MILS:Meta发布的无需训练就能让LLM获得多模态能力的方法
2025-03-28
-

2025-04-14
-

Gemini 2.5 Pro与Gemini 2.5相比较,有哪些提升?
2025-04-29
-
2025-02-24
-
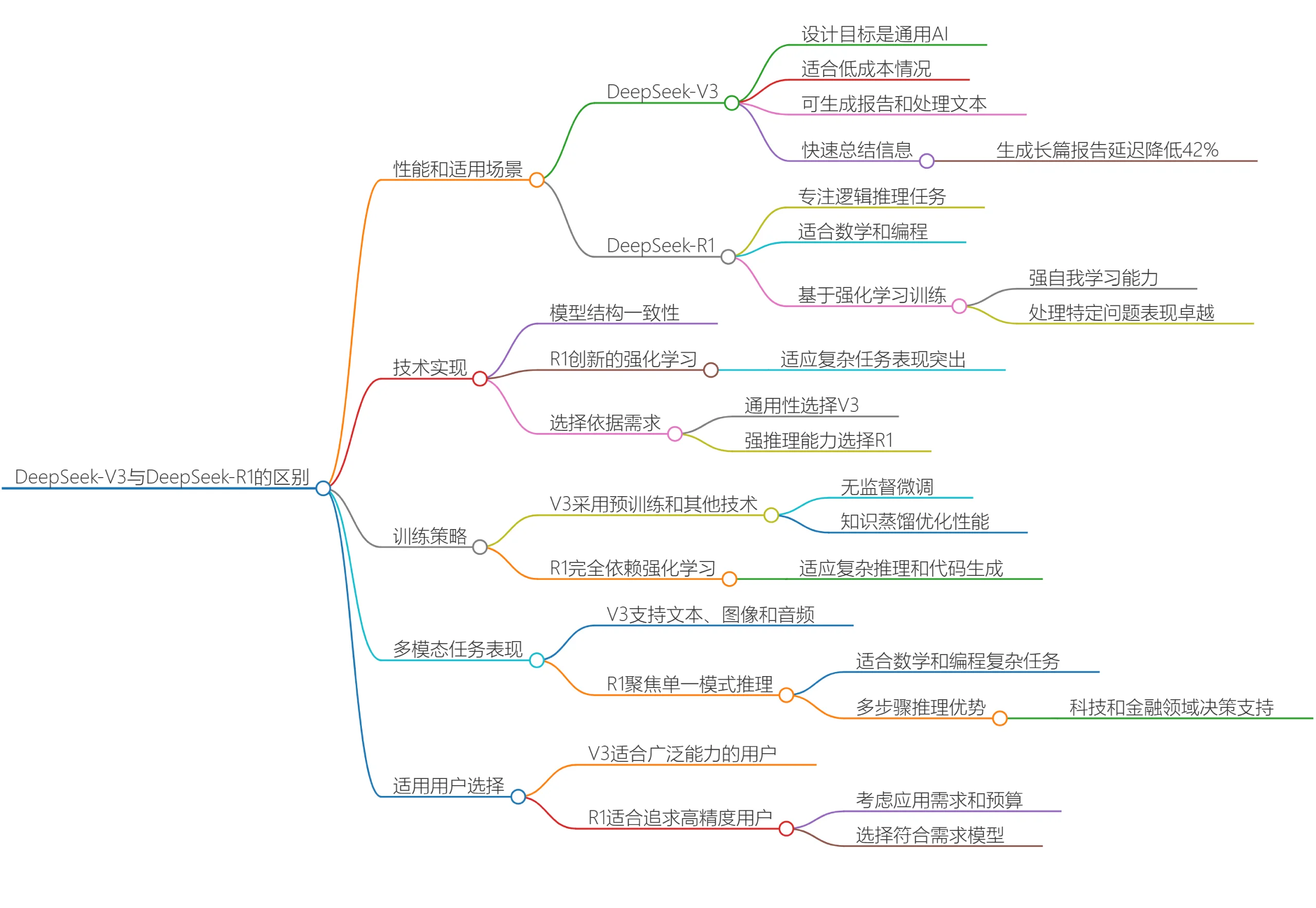
DeepSeek V3和DeepSeek R1有什么区别?哪个更适合你呢?
2025-03-20
-

2025-04-05
-

2025-04-21
-
文生图模型Ideogram 2A:更快的生成速度和更低的成本
2025-03-12
-
2025-03-28








