Speech-02:MiniMax Audio新发布的一款强大的文本转语音(TTS)模型
Speech-02是什么?
MiniMax Audio Speech-02是一款强大的文本转语音(TTS)模型,能够将任何文件或URL瞬间转化为逼真的音频 。它支持高达20万字符的单次输入,覆盖30多种语言,并带有地道口音 。此外,Speech-02还支持无限语音克隆、亚秒级流媒体处理以及多种音频格式(如FLAC、WAV、MP3和PCM) 。
Speech-02模型提供两种版本:speech-02-hd-preview(以99%的语音相似度和工作室级清晰度为特点,适合配音、有声书等需要逼真表现的场景)和speech-02-turbo-preview(在低延迟和高性能之间取得平衡,适合实时应用) 。
模型")
语言与语音能力
多语言支持:Speech-02支持30多种语言的文本转语音,包括英语、中文、日语、韩语、法语、德语、西班牙语、葡萄牙语、意大利语、阿拉伯语、俄语、土耳其语、荷兰语、乌克兰语、越南语、印地语、泰语、波兰语、罗马尼亚语、希腊语、芬兰语和印尼语等,且带有地道口音。
语音库丰富:拥有300多个真实自然的声音,支持多种语言的地道表达。
技术性能
单次输入字符数:单次输入支持高达20万字符。
流媒体处理速度:支持亚秒级流媒体处理。
模型版本:包括speech-02-hd-preview和speech-02-turbo-preview。前者以99%的语音相似度和工作室级清晰度为特点,适合配音、有声书等需要逼真表现的场景;后者则在低延迟和高性能之间取得平衡,适合实时应用。
Speech-02功能特性
无限语音克隆:能够以行业领先的质量,快速克隆出多种风格和语调的语音。
语音控制:用户可以轻松控制语音的情感、音量、速度和输出格式。
语音混合:可以将现有的语音组合起来,创造出全新的独特语音。
音频格式支持:支持FLAC、WAV、MP3和PCM等多种音频格式。
Speech-02应用场景
有声书制作:适合将长篇小说、学术论文等转化为高质量的音频内容。
播客创作:帮助播客创作者制作更具吸引力和多样性的内容。
电影与游戏配音:提供电影级低音和沉浸式音频效果。
国际会议与翻译:支持在多种语言之间即时无缝切换。
目前,Speech-02模型已经在MiniMax Audio平台及API平台上线,但国内版尚未推出。
官方链接
MiniMax Audio平台:https://www.minimax.io/audio
MiniMax Audio API平台:https://www.minimax.io/platform
-
下一篇: 最后一页
- Speech-02:MiniMax Audio新发布的一款强大的文本转语音(TTS)模型
- Saber:一款效果跟纸质手写的跨平台开源笔记应用
- MCP-Twikit:与Twitter交互的MCP服务器,应用于社交媒体分析和数据检索
- social-auto-upload:可以一键分发,自动化短视频上传的免费开源神器
- DSO:牛津大学公布的符合物理规律的3D模型优化框架项目
- Dolphin:海天瑞声与清华大学联合发布的一款面向东方语种的自动语音识别模型
- WeChatAssistant:微信智能助手插件系统
- Saber-Translator:智能检测漫画对话气泡并精准识别日文,快速翻译成中文
- 即梦AI上线3.0版本:中文文字控制能力炸裂,直接将设计师干失业了
- 先知:集代码托管、CI/CD、代码质量分析、研发效能度量于一体的研发效能平台
-
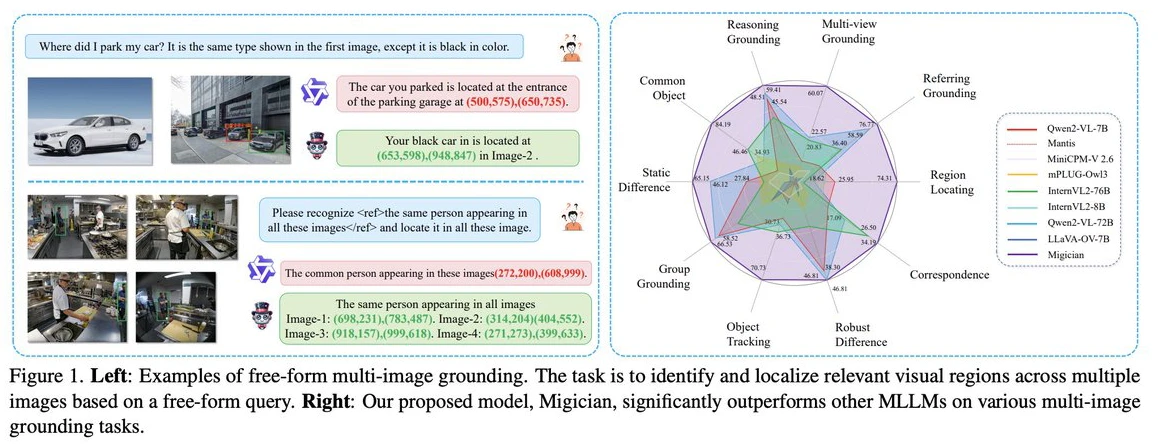
Migician:清华大学等团队出的解决复杂场景下的多图像目标定位问题的多模态模型
2025-03-11
-

MILS:Meta发布的无需训练就能让LLM获得多模态能力的方法
2025-03-28
-

2025-04-14
-
2025-02-24
-
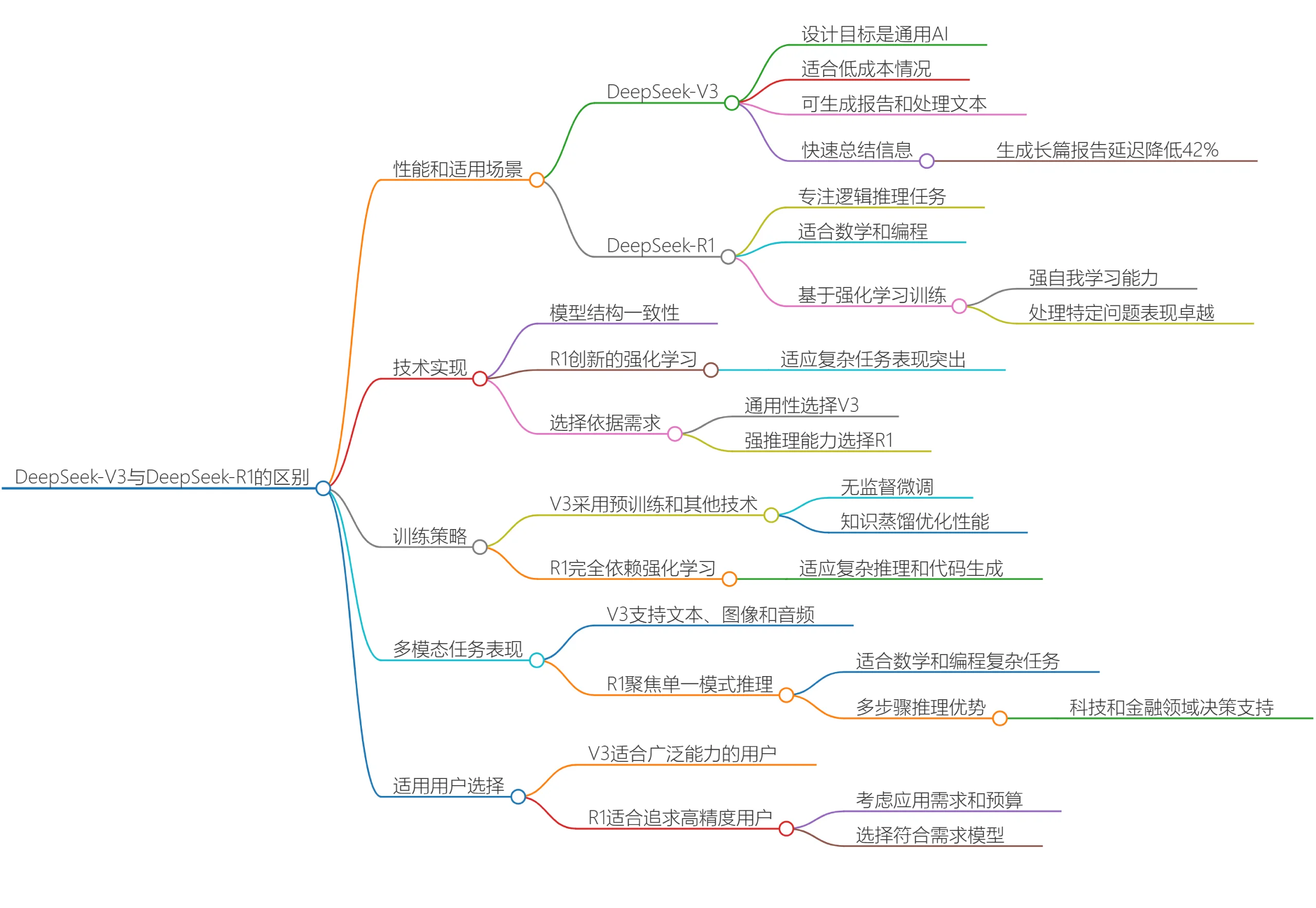
DeepSeek V3和DeepSeek R1有什么区别?哪个更适合你呢?
2025-03-20
-

2025-04-05
-

2025-04-21
-
文生图模型Ideogram 2A:更快的生成速度和更低的成本
2025-03-12
-
2025-03-28
-
HeyGem.ai:Heygen的开源平替产品,精确外貌与声音克隆,合成虚拟数字人视频
2025-04-15








