playwright-mcp:能够使大语言模型直接操控浏览器完成复杂任务
laywright-MCP是什么?
laywright-MCP 是一个结合了 Playwright 的跨浏览器能力和模型上下文协议(MCP)的开源工具,它能够使大语言模型(LLM)能够直接操控浏览器完成复杂任务,核心是让LLM通过结构化的可访问性快照与网页交互,而无需依赖屏幕截图或视觉模型,可以用来自动填写网页表单、自动收集网页信息、自动进行网页测试等
")
laywright-MCP功能特点
浏览器自动化:支持打开网页、点击元素、填写表单、截屏、执行 JavaScript 等操作。
结构化数据交互:基于 Playwright 的可访问性树生成结构化数据,无需视觉模型,适合基于文本的 LLM。
两种模式:提供默认的“快照模式”(Snapshot Mode)和“视觉模式”(Vision Mode),后者可通过截图实现视觉交互。
无头模式支持:可以在后台运行浏览器,不显示界面。
快速轻量:基于 Playwright 的轻量级架构,响应速度快。
laywright-MCP使用场景
自动化测试:创建 ai 驱动的测试场景,模拟真实用户行为。
数据提取:从复杂结构的网站中提取特定数据。
智能 Web 代理:构建能够自动执行复杂任务的代理,如预订旅行、比较价格等。
API 测试:支持发送 HTTP 请求并检查响应内容。
网页导航和表单填写
从结构化内容中提取数据
代理的通用浏览器交互
laywright-MCP安装与配置
1. 安装:通过 npm 全局安装 Playwright-MCP 服务器:
npminstall-g@executeautomation/playwright-mcp-server2. 配置:在 Claude Desktop 或其他支持 MCP 的客户端中配置 Playwright-MCP:
{"mcpServers":{"playwright":{"command":"npx","args":["-y","@executeautomation/playwright-mcp-server"]}}}laywright-MCP优势
降低门槛:允许用户通过自然语言指令控制浏览器操作,无需编写复杂代码。
高效性:基于结构化数据的交互方式比传统基于视觉的方法更高效。
灵活性:支持实时生成指令,适应动态变化的页面。
github项目:https://github.com/microsoft/playwright-mcp
-
下一篇: 最后一页
- playwright-mcp:能够使大语言模型直接操控浏览器完成复杂任务
- 如何用OpenAI的GPT-4o来制作属于自己的表情包教程
- QVQ-Max:阿里推出的视觉推理模型,能够理解图片和视频中的内容
- Paper-to-Podcast:将学术论文转换为AI播客的开源工具
- ideogram v3发布,看看有哪些新功能或改进。
- Pika新功能 :与小时候的自己合影拍视频教程指南
- ChatAnyone:阿里发布的通过音频输入生成具有丰富表情和上半身动作的肖像视频
- 豆包刚上线的深度思考与DeepSeek相比较,哪个更好?
- GhidraMCP:让AI大模型能够自主操作Ghidra进行逆向工程的开源项目
- MegaTTS 3:字节跳动推出的一款零样本文本到语音合成系统
-
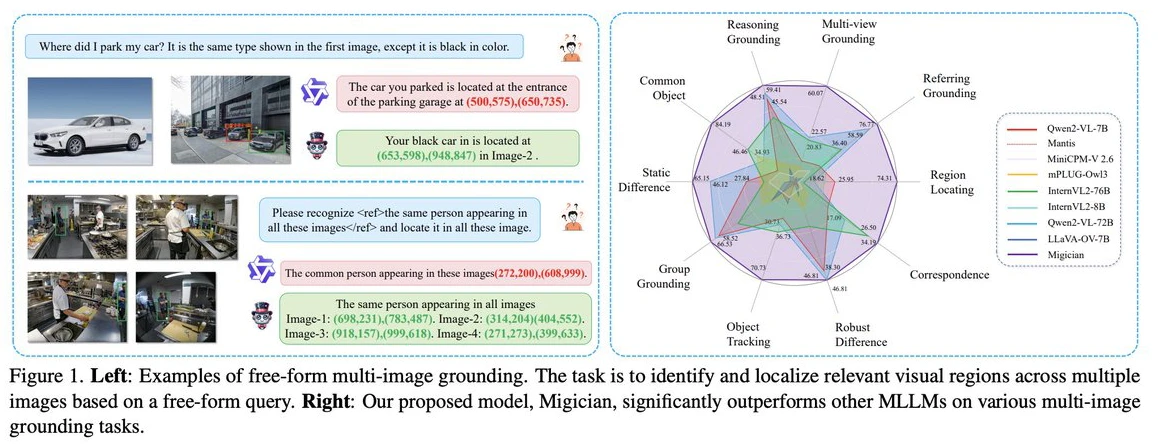
Migician:清华大学等团队出的解决复杂场景下的多图像目标定位问题的多模态模型
2025-03-11
-

MILS:Meta发布的无需训练就能让LLM获得多模态能力的方法
2025-03-28
-

2025-04-14
-
2025-02-24
-
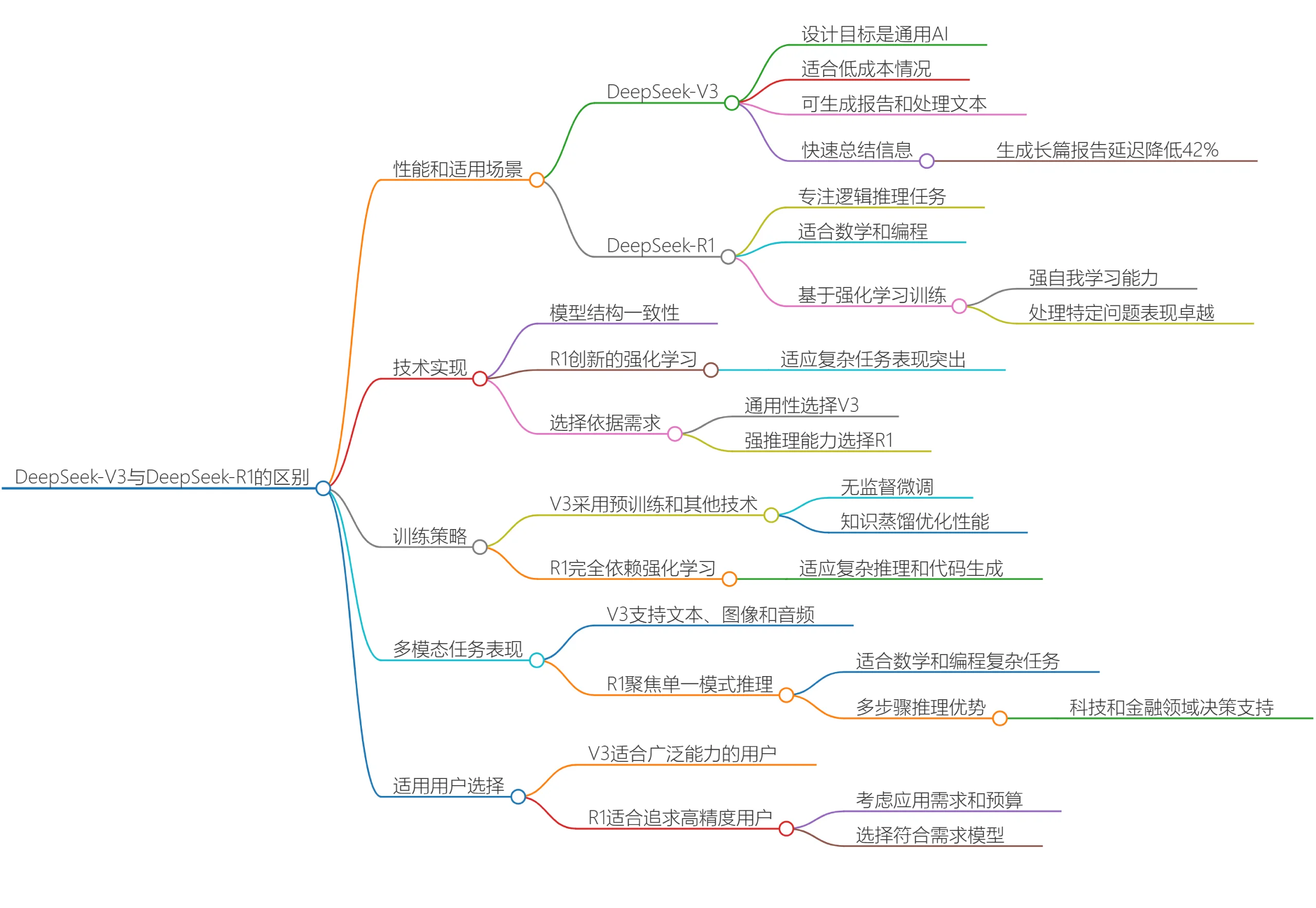
DeepSeek V3和DeepSeek R1有什么区别?哪个更适合你呢?
2025-03-20
-

2025-04-05
-

2025-04-21
-
文生图模型Ideogram 2A:更快的生成速度和更低的成本
2025-03-12
-
2025-03-28
-
HeyGem.ai:Heygen的开源平替产品,精确外貌与声音克隆,合成虚拟数字人视频
2025-04-15








