Dagster: 现代数据工程的全生命周期数据资产编排平台
Dagster简介
Dagster是一个强大的数据编排平台,专为开发、生产和观察数据资产而设计。它提供了一套完整的工具和框架,帮助数据工程师和数据科学家更高效地管理复杂的数据流程。作为一个现代化的数据工程工具,Dagster在整个数据开发生命周期中发挥着关键作用。
核心理念
Dagster的核心理念是将数据处理流程视为一系列相互关联的资产。在Dagster中,你可以使用Python函数来声明你想要构建的数据资产。Dagster会帮助你在适当的时候运行这些函数,并保持资产的最新状态。这种基于资产的方法使得数据流程更加清晰和易于管理。
主要特性
云原生设计: Dagster从设计之初就考虑了云环境的特性,能够无缝地在各种云平台上运行。
集成的血缘分析: Dagster提供了强大的数据血缘分析功能,帮助用户理解数据资产之间的关系和依赖。
可观测性: 通过内置的监控和日志功能,Dagster为数据流程提供了全面的可观测性。
声明式编程模型: Dagster采用声明式的编程模型,使得数据流程的定义更加直观和易于理解。
优秀的可测试性: Dagster内置了强大的测试框架,支持单元测试、集成测试等多种测试方式。
Dagster的工作原理
Dagster的工作流程主要围绕着"资产"(Asset)的概念展开。在Dagster中,资产可以是各种形式的数据产物,如数据表、数据集、机器学习模型或报告等。
资产定义
以下是一个简单的Dagster资产定义示例:
from dagster import assetfrom pandas import DataFrame, read_html, get_dummiesfrom sklearn.linear_model import LinearRegression@assetdef country_populations() -> DataFrame: df = read_html("https://tinyurl.com/mry64ebh")[0] df.columns = ["country", "pop2022", "pop2023", "change", "continent", "region"] df["change"] = df["change"].str.rstrip("%" ).str.replace("−", "-").astype("float") return df@assetdef continent_change_model(country_populations: DataFrame) -> LinearRegression: data = country_populations.dropna(subset=["change"]) return LinearRegression().fit(get_dummies(data[["continent"]]), data["change"])@assetdef continent_stats(country_populations: DataFrame, continent_change_model: LinearRegression) -> DataFrame: result = country_populations.groupby("continent").sum() result["pop_change_factor"] = continent_change_model.coef_ return result在这个例子中,我们定义了三个相互关联的资产:country_populations、continent_change_model和continent_stats。每个资产都是通过@asset装饰器定义的Python函数。
资产图
Dagster会自动根据资产之间的依赖关系构建资产图。这个图可以在Dagster的Web UI中可视化展示,帮助用户理解数据流程的结构。

Dagster的主要优势
全生命周期支持: Dagster可以在数据开发的各个阶段使用,从本地开发、单元测试、集成测试,到预发环境,再到生产环境。
灵活性: Dagster支持多种数据处理范式,包括基于任务的工作流和基于资产的数据管理。
可扩展性: Dagster提供了丰富的插件生态系统,可以轻松集成各种数据工具和服务。
强大的调度和编排能力: Dagster提供了灵活的调度选项和强大的工作流编排功能。
优秀的开发者体验: Dagster的设计注重开发者体验,提供了直观的API和全面的文档。
Dagster与现代数据栈的集成
Dagster提供了大量的集成选项,可以无缝对接现代数据栈中的各种工具。以下是一些常见的集成:
数据仓库: Snowflake, BigQuery, Redshift数据湖: Delta Lake, Apache IcebergETL工具: dbt, Apache Spark数据质量: Great Expectations调度系统: Apache Airflow容器化和编排: Docker, Kubernetes云平台: AWS, GCP, Azure这些集成使得Dagster可以灵活地适应各种数据架构和技术栈。
Dagster的实际应用场景
数据仓库建设: 使用Dagster编排复杂的ETL流程,构建企业数据仓库。
机器学习工作流: 管理从数据准备到模型训练、评估和部署的整个ML流程。
数据质量监控: 利用Dagster的可观测性功能,实时监控数据质量。
报表自动化: 自动化生成和分发各种业务报表。
数据治理: 利用Dagster的元数据管理功能,实现数据血缘追踪和数据资产管理。
快速入门指南
要开始使用Dagster,首先需要安装Dagster及其Web UI:
pip install dagster dagster-webserver这将安装两个主要组件:
dagster: 核心编程模型dagster-webserver: 用于开发和操作Dagster作业和资产的Web UI服务器安装完成后,你可以创建一个简单的Dagster项目,定义一些资产,然后使用dagster dev命令启动开发服务器。
Dagster社区和生态系统
Dagster拥有一个活跃的开源社区,提供了丰富的资源和支持:
GitHub仓库: https://github.com/dagster-io/dagster官方文档: https://docs.dagster.io/Slack社区: https://dagster.io/slack博客: https://dagster.io/blog社区成员可以通过这些渠道分享知识、获取帮助,并为这个开源项目做出贡献。
结论
Dagster作为一个现代化的数据编排平台,为数据工程师提供了强大的工具来管理复杂的数据流程。它的资产中心设计、全生命周期支持和丰富的集成选项,使其成为构建可靠、可扩展数据平台的理想选择。无论是初创公司还是大型企业,Dagster都能为其数据工程实践带来显著的改进。
随着数据工程领域的不断发展,Dagster也在持续演进,不断引入新的特性和改进。对于希望提升数据工程能力的组织和个人来说,深入学习和使用Dagster无疑是一个明智的选择。
-
下一篇: 最后一页
-
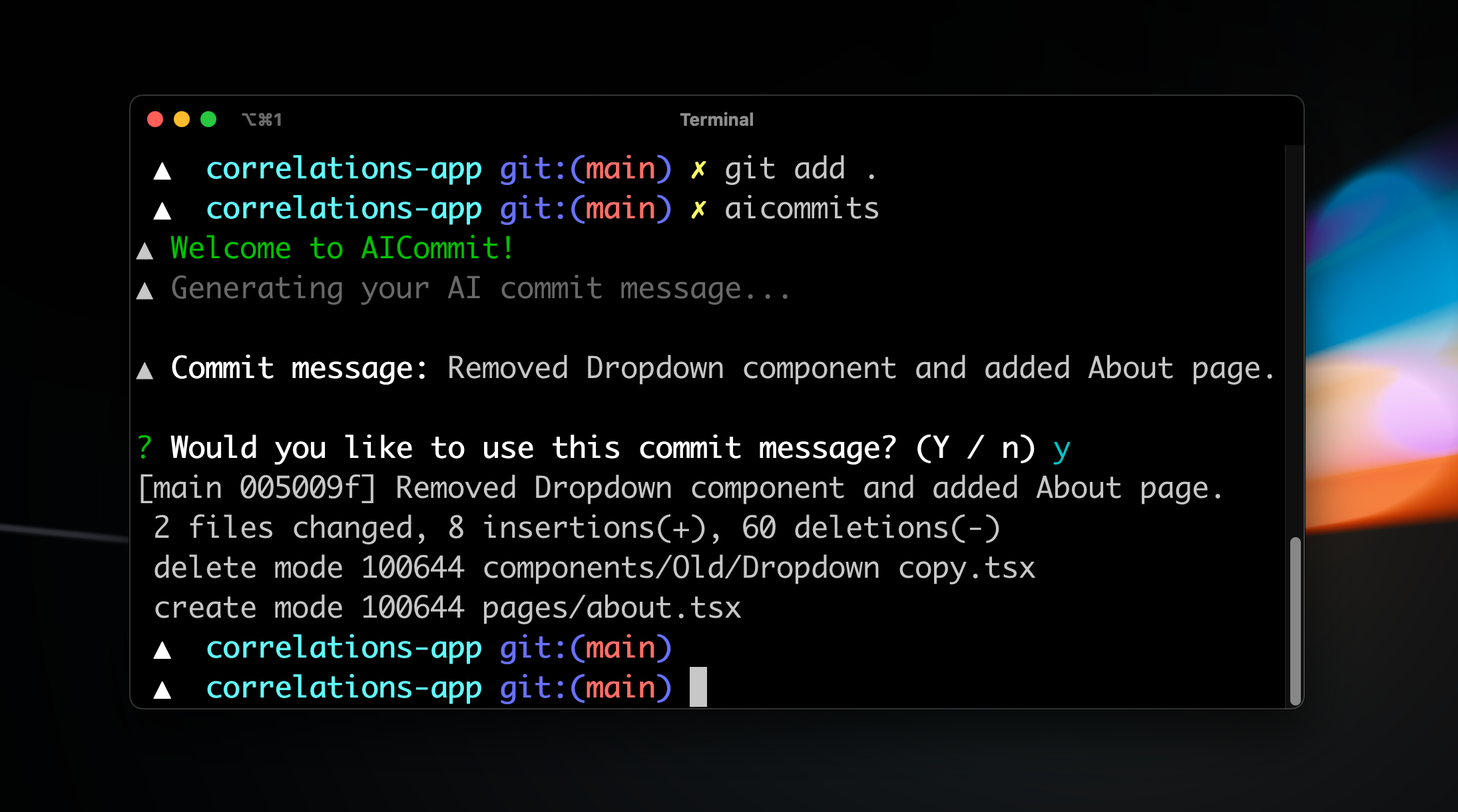
aicommits学习资料汇总-AI驱动的Git提交消息生成器
2025-01-06
-
2025-01-15
-

-

2025-02-07
-
2025-01-10
-

DB-GPT:12.7k星星!让大模型与数据库的交互更简单便捷,助力开发
2025-01-21
-
2025-01-31
-
2025-02-14
-

2025-01-06
-
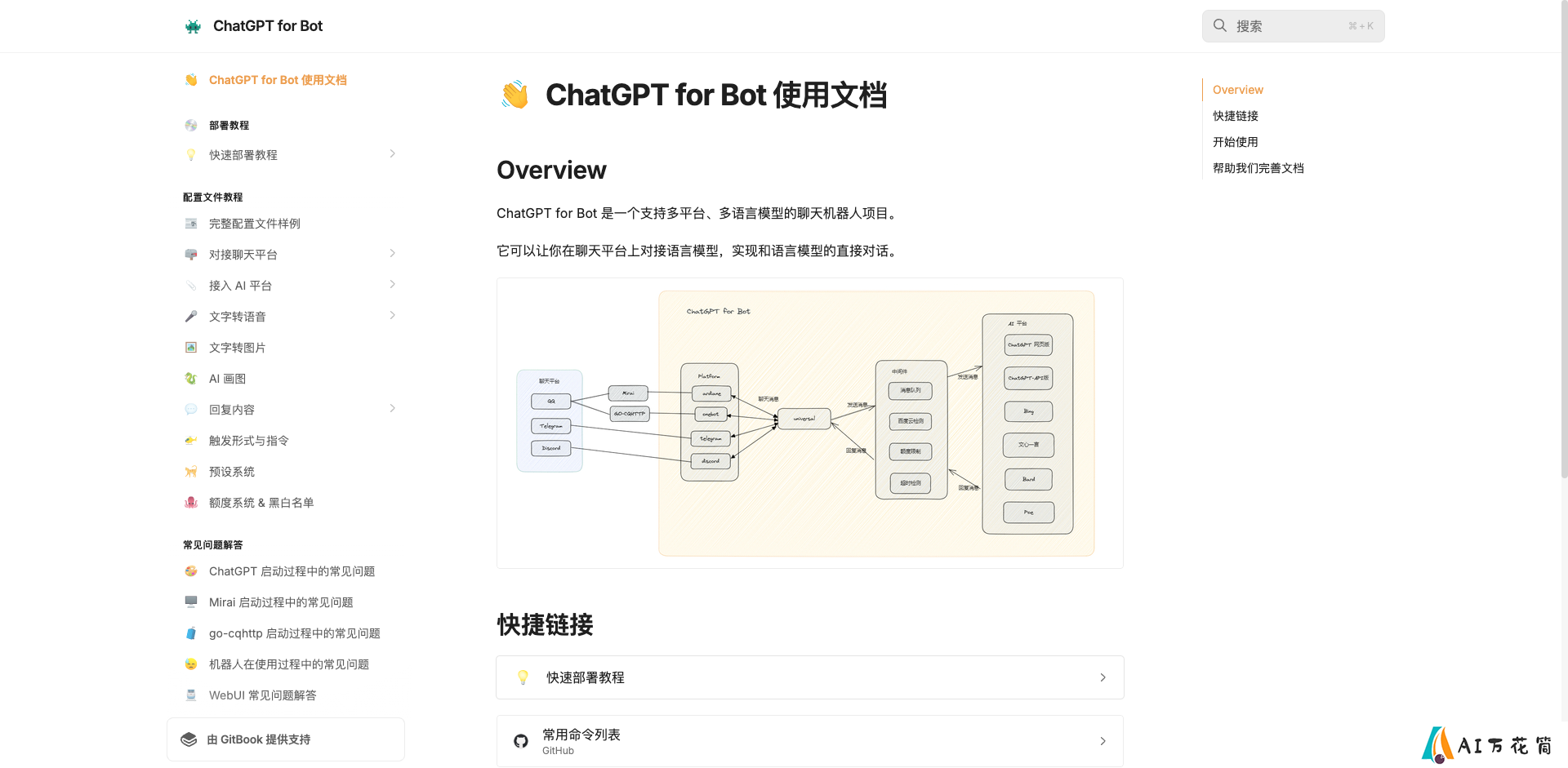
ChatGPT-Mirai-QQ-Bot: 多功能AI聊天机器人的一键部署解决方案
2025-01-16









