AniSora:B站开源的动漫视频生成模型
AniSora是什么?
AniSora是哔哩哔哩在2025年5月12日开源的一个ai动画视频生成系统。它能轻松生成各种风格的动漫视频,比如番剧片段、国创动画、漫画改编、VTuber内容、动画PV,还有鬼畜视频。这个系统在保持角色形象和动作流畅性方面做得很不错,可以说是目前最先进的动画视频生成模型。

AniSora功能
图像到视频生成:根据单张图片生成连贯的动画视频,适用于从静态画面扩展为动态场景。
帧插值:支持关键帧插值,基于生成中间帧实现平滑过渡,减少动画制作中手工绘制的工作量。
局部图像引导:支持用户指定特定区域进行动画生成。
时空控制:结合时间和空间的控制能力,支持首帧、尾帧、多帧引导等多种方式,实现精准的动画创作。
AniSora模型特点
针对性优化:相比自然视频,动漫视频在风格上更具表现力和抽象性,传统的生成模型往往难以精准复现角色神态、动作节奏以及夸张的镜头语言。AniSora 针对这些特性做了针对性优化,目标是在不牺牲创意表达的前提下,提升视频生成效率。
多样化风格支持:能够一键生成多种风格的视频片段,涵盖系列剧集、中国原创动画、漫画改编、VTuber 内容、动漫 PV 甚至是鬼畜类创作。
低门槛创作:对于有实际制作需求的个人或工作室而言,AniSora 是极具吸引力的创作工具。
AniSora核心模块
数据处理流水线:预处理了超过 1000 万对高质量的文本 - 视频数据,为训练提供了坚实基础。
可控生成模型:引入时空掩码模块,支持图生视频、关键帧插值、局部图像引导等功能,能够适配各种创作需求。
评测体系:构建了包含 948 段多样化动画片段的评测数据集,结合双盲人评审和 VBench 评分系统,对人物一致性、动作衔接等维度进行打分。
AniSora技术原理
扩散模型(Diffusion Model):基于扩散模型架构,逐步去除噪声生成高质量的视频内容。
时空掩码模块(Spatiotemporal Mask Module):支持模型在生成过程中对特定时间和空间区域进行控制,例如掩码指定哪些帧或哪些区域需要生成动画,实现局部引导和关键帧插值等功能。
3D 因果变分自编码器(3D Causal VAE):用于对视频的时空特征进行编码和解码,将视频压缩到低维的潜在空间,降低计算复杂度,同时保留关键的时空信息。
Transformer 架构:结合 Transformer 的强大建模能力,基于注意力机制捕捉视频中的复杂时空依赖关系,使模型能够处理长序列数据,生成更连贯的视频内容。
监督微调(Supervised Fine-Tuning):在预训练的基础上,用大量的动画视频数据进行监督微调,通过多种策略(如弱到强的训练策略、多任务学习等)提高模型的泛化能力和生成质量。
数据处理流水线:基于场景检测、光学流分析、美学评分等技术,从大量原始动画视频中筛选出高质量的训练数据,确保训练数据的质量和多样性。
开源地址
https://github.com/bilibili/Index-anisora/tree/main
https://huggingface.co/IndexTeam/Index-anisora
https://www.modelscope.cn/organization/bilibili-index
-
下一篇: 最后一页
-
Codemcp:一款将Claude Pro转变为结对编程助手的工具
2025-05-29
-

-
2025-05-26
-
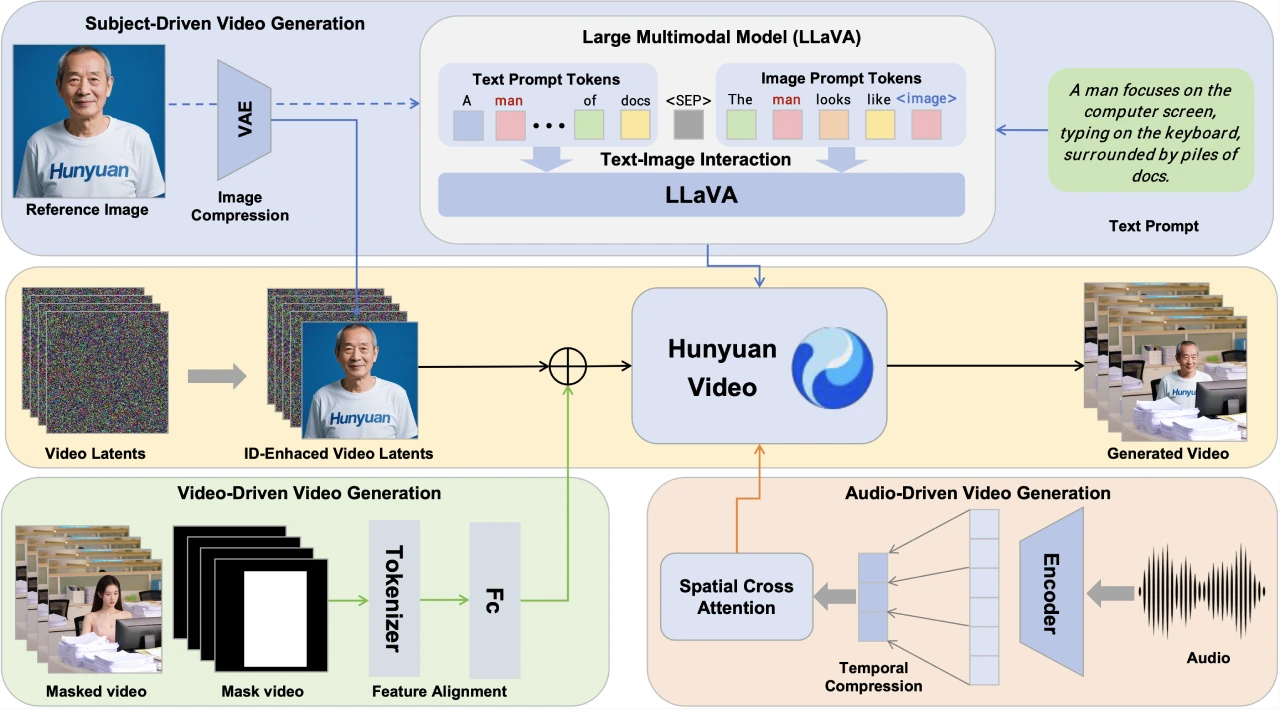
HunyuanCustom:腾讯混元推出并开源的全新的多模态定制化视频生成工具
2025-05-23
-

2025-05-29
-
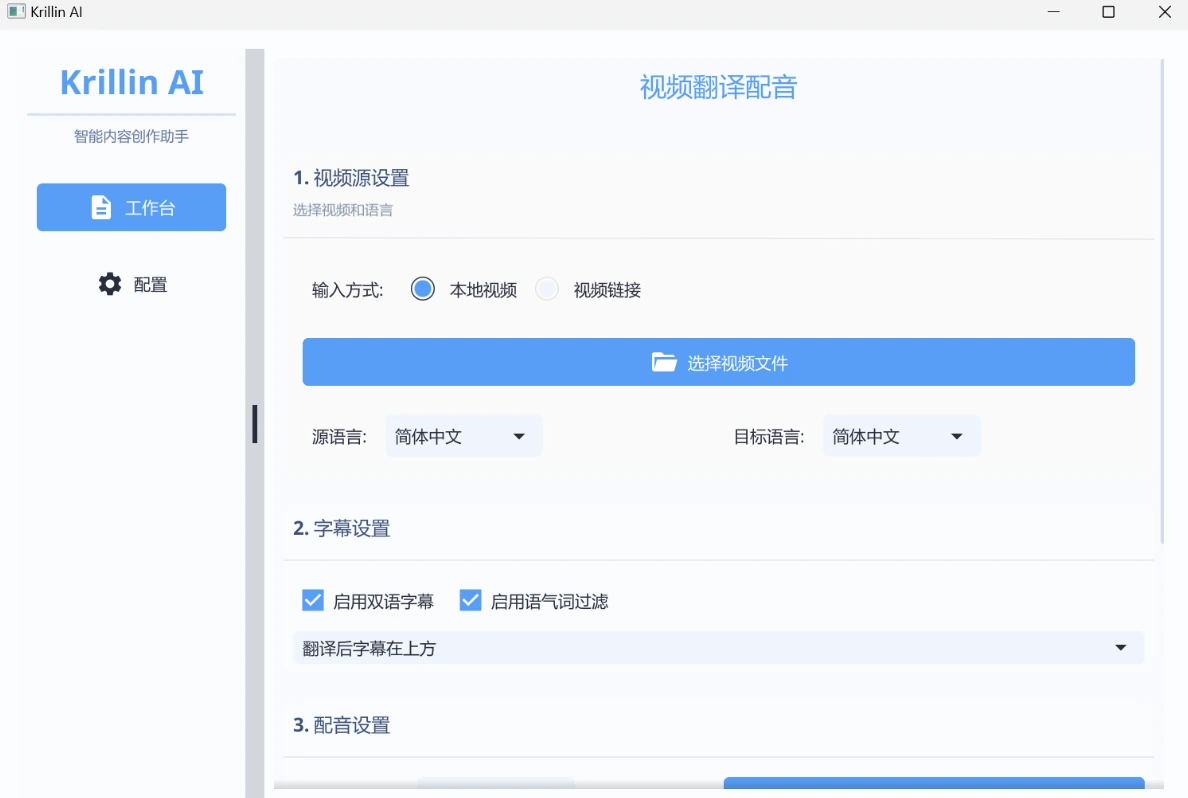
Krillin AI:基于LLMs的专业级视频翻译、配音和语音克隆工具
2025-05-18
-
opik-mcp:Opik平台实现的开源MCP,支持多种传输机制,能与IDE集成
2025-05-26
-
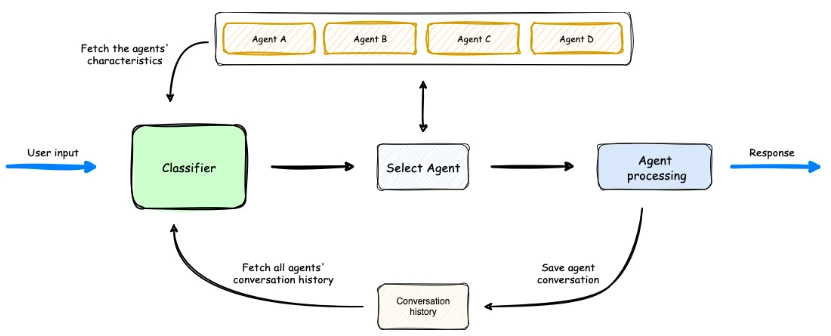
Agent Squad:用于管理多个AI智能体和处理复杂对话的开源框架
2025-05-24
-
-

EasyControl:一款AI图像风格转换工具框架,可精准还原吉卜力风格
2025-05-18










-
- 1Versatile-OCR-Program:能够从复杂的材料(如考试试卷)中提取结构化数据的OCR
- 2拍照问夸克:基于AI超级框的视觉理解和推理模型能力
- 3HunyuanCustom:腾讯混元推出并开源的全新的多模态定制化视频生成工具
- 4可灵AI 2.0更新了哪些功能?
- 5Krillin AI:基于LLMs的专业级视频翻译、配音和语音克隆工具
- 6opik-mcp:Opik平台实现的开源MCP,支持多种传输机制,能与IDE集成
- 7Agent Squad:用于管理多个AI智能体和处理复杂对话的开源框架
- 8Embodied-Reasoner:浙江大学和阿里巴巴达摩院等机构联合提出的一个开源的多模态具身模型
- 9EasyControl:一款AI图像风格转换工具框架,可精准还原吉卜力风格