MoCha:Meta推出的首个能实现电影级说话角色生成的DiT模型
MoCha是什么?
MoCha 是由 Meta 和多伦多大学联合开发的一个 ai 模型,能够根据语音或文本输入生成带有完整人物形象的高质量角色动画视频,生成动作连贯流畅,支持多角色对话,是首个能实现电影级对话角色生成的DiT模型。

MoCha功能特点
语音驱动的角色动画生成:用户输入语音,MoCha 可以生成与语音内容同步的角色嘴型、面部表情、手势及身体动作。
文本驱动的角色动画生成:用户仅输入文本脚本,MoCha 会先自动合成语音,再驱动角色进行完整的口型和动作表现。
多角色轮番对话生成:MoCha 提供结构化提示模板与角色标签,能自动识别对话轮次,并实现角色间“你来我往”的自然对话呈现。
支持多种应用场景:包括虚拟主播、动画影视创作、教育内容创作、数字人客服和数字遗产等。

MoCha优势
生成内容接近电影级:与传统的“Talking Head”技术不同,MoCha 能够生成全身动画,让角色动作更加自然。
降低创作门槛:无需动捕设备和 3D 建模经验,降低了内容创作的门槛。
MoCha应用:
虚拟主播:自动生成日常 Vlog、角色问答
动画影视创作:AI 自动配音 + 自动动画,降低制作成本
教育内容创作:AI 老师角色讲课或互动
数字人客服:拟人化企业客服、咨询角色
数字遗产:为历史人物或故人打造动态影像

相关链接
项目主页: https:// congwei1230.github.io/MoCha/
论文: https:// arxiv.org/pdf/2503.23307
- MoCha:Meta推出的首个能实现电影级说话角色生成的DiT模型
- Amazon Nova Act:亚马逊推出的具备操控网页浏览器并自主执行简单任务的的AI智能体
- Speech-02:MiniMax Audio新发布的一款强大的文本转语音(TTS)模型
- Saber:一款效果跟纸质手写的跨平台开源笔记应用
- MCP-Twikit:与Twitter交互的MCP服务器,应用于社交媒体分析和数据检索
- social-auto-upload:可以一键分发,自动化短视频上传的免费开源神器
- DSO:牛津大学公布的符合物理规律的3D模型优化框架项目
- Dolphin:海天瑞声与清华大学联合发布的一款面向东方语种的自动语音识别模型
- WeChatAssistant:微信智能助手插件系统
- Saber-Translator:智能检测漫画对话气泡并精准识别日文,快速翻译成中文
-
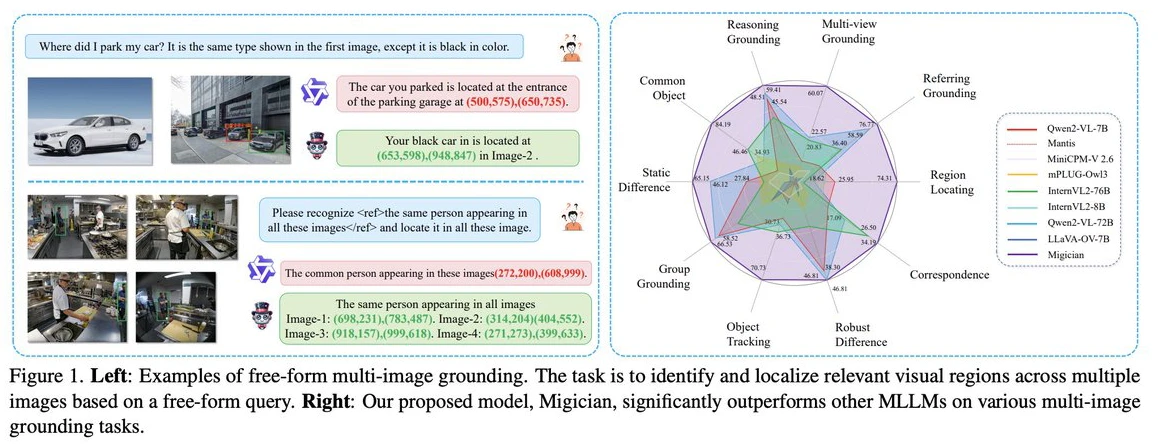
Migician:清华大学等团队出的解决复杂场景下的多图像目标定位问题的多模态模型
2025-03-11
-

MILS:Meta发布的无需训练就能让LLM获得多模态能力的方法
2025-03-28
-

2025-04-14
-
2025-02-24
-
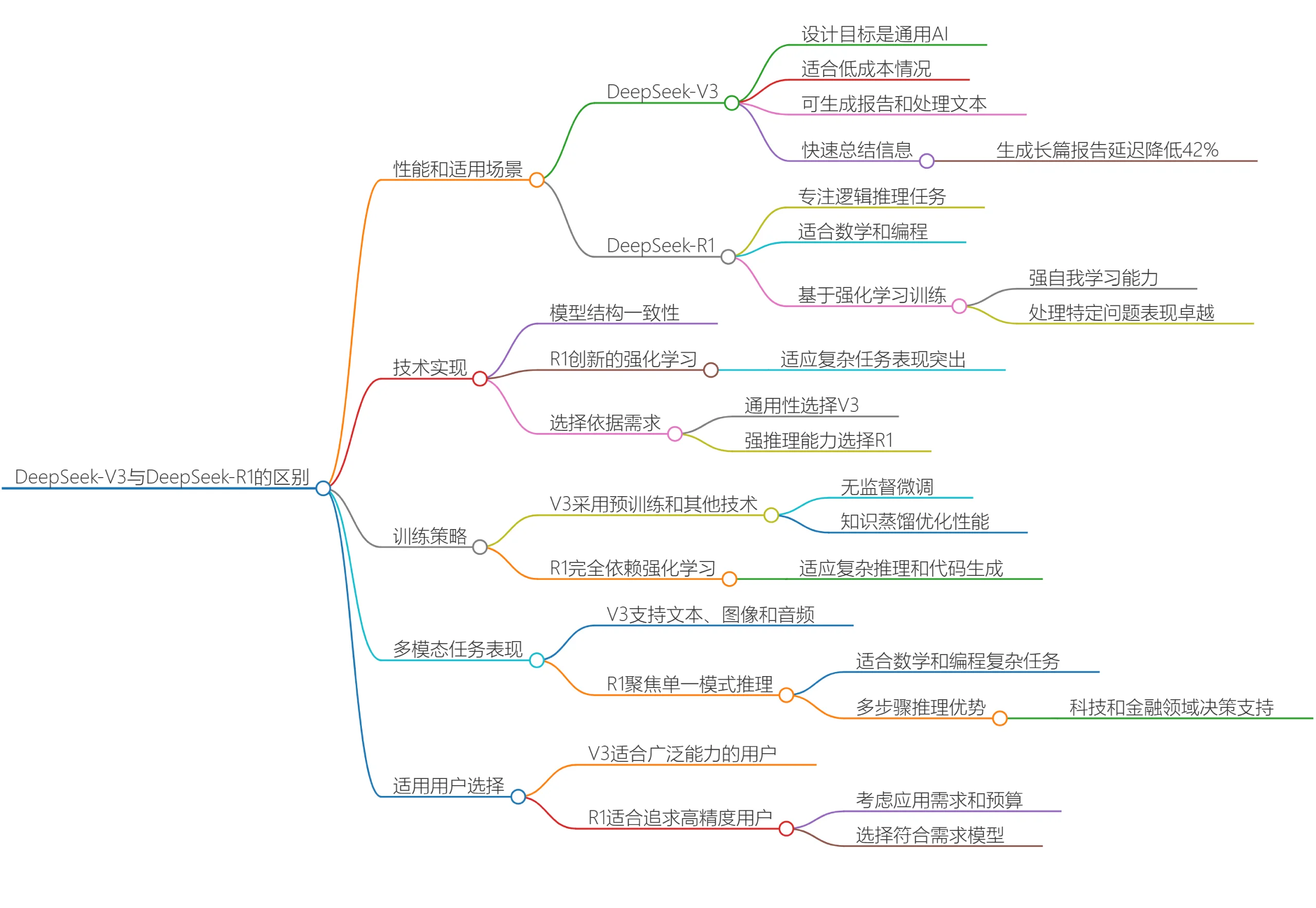
DeepSeek V3和DeepSeek R1有什么区别?哪个更适合你呢?
2025-03-20
-

2025-04-05
-

2025-04-21
-
文生图模型Ideogram 2A:更快的生成速度和更低的成本
2025-03-12
-
2025-03-28
-
HeyGem.ai:Heygen的开源平替产品,精确外貌与声音克隆,合成虚拟数字人视频
2025-04-15








