Stable Virtual Camera:使用一张图片,可以生成360度旋转的3D视频
Stable Virtual Camera是什么?
Stable Virtual Camera 是由 Stability AI 推出的一款用于NVS 的多视角扩散模型。它能够根据任意数量的输入视角及其对应的相机参数,生成目标相机视角下的新图像。当所有相机形成一条轨迹时,生成的视角在 3D 上具有一致性、时间上平滑,并且正如其名称所暗示的那样——“稳定”,能够生成无缝的轨迹视频。

Stable Virtual Camera功能
多视角输入:可以接受从 1 到 32 张输入图像,性能随着输入视角的增加而提升,尤其是在处理大型场景时。
灵活的图像分辨率:尽管模型仅在 576×576 的正方形图像上进行训练,但能够以零样本的方式生成不同宽高比的目标视角。
长视频生成与闭环一致性:能够生成长达 1000 帧的视频,并在相机返回到同一位置时保持 3D 一致性。
采样多样性:在给定稀疏输入视角时,能够捕捉视角合成的不确定性,并生成不同的可能场景。
基准测试:建立了一个全面的基准,用于在不同数据集和设置下评估 NVS 方法。Stable Virtual Camera 达到了新的最佳性能。
Stable Virtual Camera应用
广告和营销:快速生成吸引人的产品展示视频。
内容创作:帮助艺术家和设计师将静态图像转化为动态视频。
教育和培训:将教材中的静态插图转化为 3D 视频,增强学习体验。
数字电影和 3D 动画:为影视制作提供新的可能性。
Stable Virtual Camera使用方法
1. 获取代码和模型
代码:从 GitHub 克隆代码。链接见文章末尾。
模型权重:从 Hugging Face 下载模型文件。下载链接见文章末尾。
2. 安装依赖
运行以下命令安装所需依赖:
pipinstall-rrequirements.txt3. 运行方式
交互式使用(Gradio 演示)
启动 Gradio 演示:
pythongradio_demo.py通过图形界面上传图片并设置参数,生成 3D 视频。
命令行使用(CLI)
使用命令行运行:
pythondemo.py--data_path--output_path--camera_path示例:
pythondemo.py--data_path./input_images--output_path./output_video--camera_pathspiral4. 输入和输出
输入:支持 1 到 32 张 2D 图像,需提供相机参数。
输出:生成不同宽高比(如 1:1、9:16、16:9)的 3D 视频,支持长达 1000 帧。
GitHub 代码仓库:https://github.com/Stability-ai/stable-virtual-camera
Hugging Face 模型页面:https://huggingface.co/stabilityai/stable-virtual-camera
项目主页:https://stable-virtual-camera.github.io/
论文:https://arxiv.org/abs/2503.14489
-
下一篇: 最后一页
- Stable Virtual Camera:使用一张图片,可以生成360度旋转的3D视频
- SmolDocling:将复杂的文档转换为结构化文本的轻量型视觉语言模型
- CSGHub Server: 开源大模型资产管理平台的强大后端
- OpenChat: 革新开源语言模型的新篇章
- Dagster: 现代数据工程的全生命周期数据资产编排平台
- PocketFlow:一款核心代码只有100行的极简LLM框架
- Julia 编程语言:高性能科学计算的新选择
- Valetudo:让你的扫地机器人脱离云端控制
- Step-Video-TI2V:阶跃星辰开源的一款AI文生视频和图生视频模型
- OptaPlanner: 强大的Java约束求解器
-
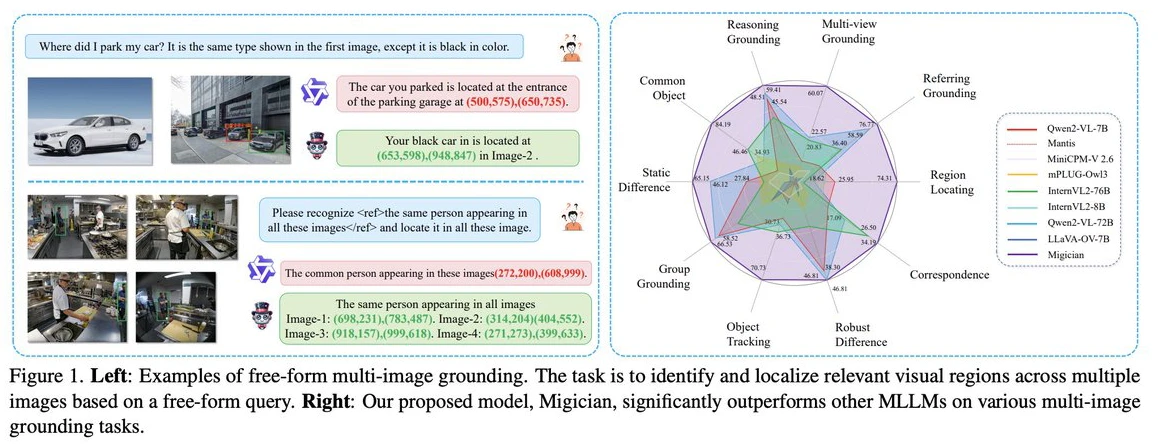
Migician:清华大学等团队出的解决复杂场景下的多图像目标定位问题的多模态模型
2025-03-11
-

MILS:Meta发布的无需训练就能让LLM获得多模态能力的方法
2025-03-28
-

2025-04-14
-

Gemini 2.5 Pro与Gemini 2.5相比较,有哪些提升?
2025-04-29
-
2025-02-24
-
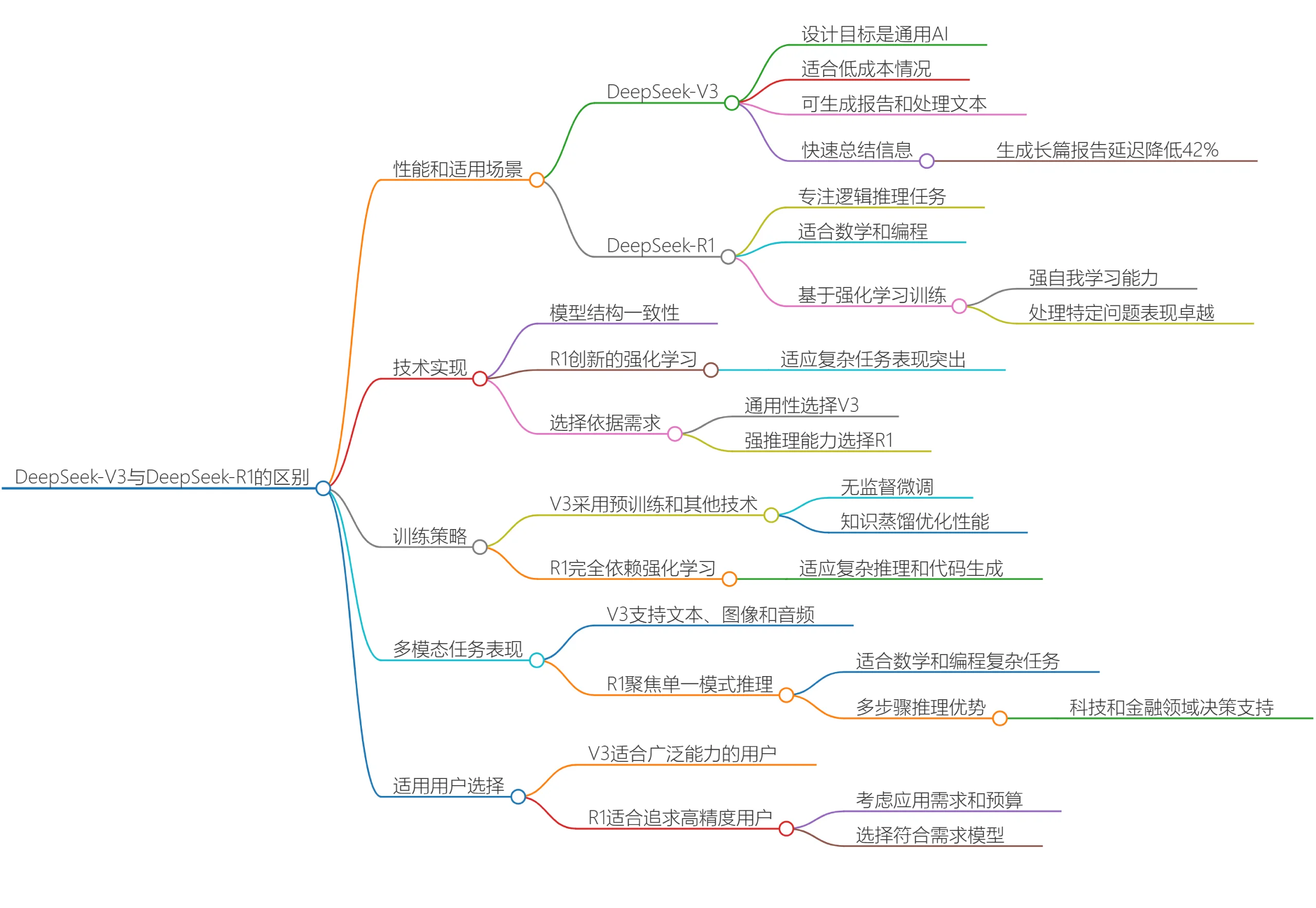
DeepSeek V3和DeepSeek R1有什么区别?哪个更适合你呢?
2025-03-20
-

2025-04-05
-

2025-04-21
-
文生图模型Ideogram 2A:更快的生成速度和更低的成本
2025-03-12
-
2025-03-28








