Insert Anything:开源图片编辑框架,可以换脸、换服装等功能
Insert Anything 介绍
Insert Anything 是一个由浙江大学、哈佛大学和南洋理工大学联合提出的统一图像插入框架,可以将参考图像中的对象无缝集成到目标场景中,支持多种实际应用场景,如艺术创作、逼真的脸部交换、电影场景构图、虚拟服装试穿、配饰定制和数字道具更换。

Insert Anything技术原理1. AnyInsertion 数据集
规模与内容:该框架基于一个包含 12 万个提示-图像对的 AnyInsertion 数据集,涵盖了人物、物体和服装插入等多种任务。
多控制模式:数据集支持两种控制模式,即掩码提示(58K 对)和文本提示(101K 对),为模型提供了丰富的训练样本。
2. Diffusion Transformer (DiT)
多模态注意力机制:Insert Anything 利用 DiT 的多模态注意力机制,支持掩码和文本引导的编辑。该机制通过图像分支和文本分支分别处理视觉输入和文本描述,然后通过多模态注意力融合这些信息。
图像分支:处理参考图像、源图像和掩码,提取视觉特征并与噪声拼接。
文本分支:编码文本描述以提供语义引导。
3. 上下文编辑机制
双联画与三联画提示策略:
掩码提示双联画:左侧为参考图像,右侧为带有掩码的目标图像。
文本提示三联画:左侧为参考图像,中间为源图像,右侧为文本生成的结果。
功能:该机制将参考图像视为上下文信息,通过隐式交互确保插入元素与目标场景的视觉一致性,同时保留其独特特征。
优势
通用性:单一模型能够处理多种插入任务,避免了为每个任务单独训练模型。
灵活性:支持掩码和文本两种控制模式,满足不同用户的编辑需求。
视觉一致性:通过上下文编辑机制,确保插入元素与目标场景自然融合。
Insert Anything应用场景
艺术创作:将艺术元素无缝插入到不同的背景中。
商业广告:将产品图像插入到广告场景中。
流行文化创作:将流行文化元素插入到相关场景中。
项目链接
项目主页:https://song-wensong.github.io/insert-anything/
论文:https://arxiv.org/abs/2504.15009
Github:https://github.com/song-wensong/insert-anything
-
下一篇: 最后一页
- Insert Anything:开源图片编辑框架,可以换脸、换服装等功能
- Agent Squad:用于管理多个AI智能体和处理复杂对话的开源框架
- Arxiv Daily AIGC:一个arXiv论文爬虫、分析和整理自动化工具
- Figma Make: Figma推出的设计师的全新编程工具
- ZeroSearch:阿里巴巴开源的一种创新大模型搜索引擎框架
- HunyuanCustom:腾讯混元推出并开源的全新的多模态定制化视频生成工具
- 天猫精灵Q糖系列音箱
- ZenCtrl:单张主体图像生成多视角、多场景的高分辨率图像
- FlowGram.AI:字节跳动开发的一款开源的基于节点的工作流构建引擎
- DeerFlow:基于LangChain和LangGraph框架的一款智能研究助手
-
2025-05-07
-

2025-05-13
-

2025-05-02
-
-
DeepPavlov:开源对话系统和聊天机器人的深度学习框架
2025-05-09
-
2025-05-15
-

Math.NET Numerics: 强大的 .NET 数值计算库
2025-05-01
-

2025-05-04
-
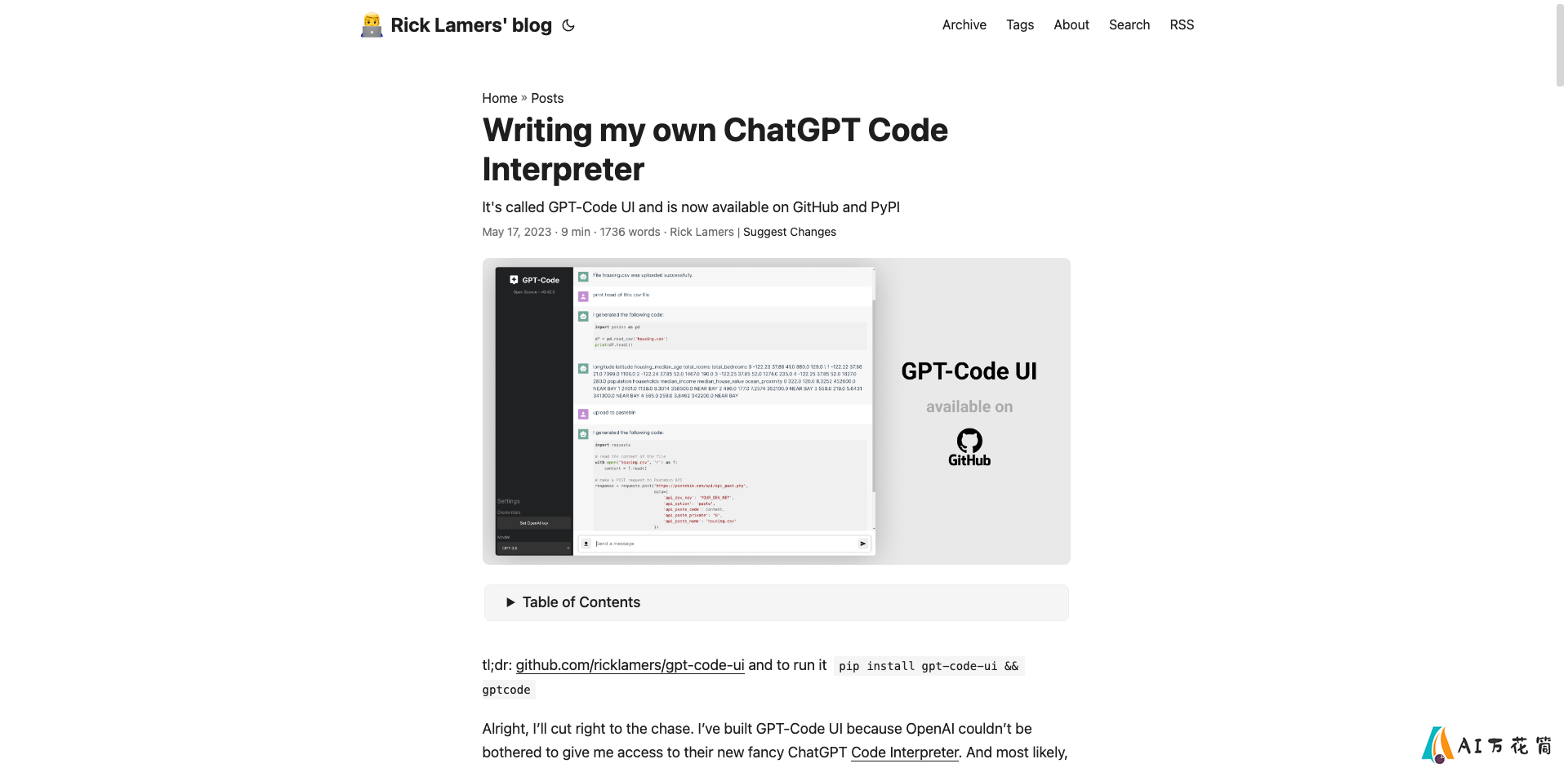
GPT-Code UI: 开源实现OpenAI的ChatGPT代码解释器
2025-05-07
-

2025-05-13









