OpenAI GPT-4o模型推出重大更新:为ChatGPT增加了图像生成和编辑功能
Openai于2025年3月25日正式宣布在GPT-4o模型中集成图像编辑和视觉生成功能,用户可以通过对话式来生成图像、修改现有视觉内容,甚至设计复杂的材料,如图表、菜单和地图等。

功能特点:
实时迭代:用户可以实时迭代图像请求,例如要求生成“城市中的蜗牛”,然后通过改变背景或添加配饰来细化场景。
复杂指令处理:该系统能够处理更复杂的图像构图指令。
文本渲染改进:GPT-4o在图像中渲染清晰且结构化的文本方面有了显著提升,使其能够更好地生成信息图表、图表、标志等专业视觉内容。
“修复”功能:用户可以对现有图像进行“修复”,编辑前景和背景元素,即使照片中有人物也适用。
性能与速度
虽然GPT-4o处理图像请求的速度比其前身DALL·E 3慢,但生成的图像更准确、更详细。图像生成可能需要长达一分钟的时间。
数据训练
OpenAI表示,GPT-4o的图像能力训练使用了“公开可用的数据”,以及来自合作伙伴(如Shutterstock)的专有内容。
技术改进
多模态生成:GPT-4o的图像生成器与文本生成器集成在同一模型中,能够更好地结合文本和图像。
自回归生成方式:与DALL-E 3等扩散模型不同,GPT-4o采用自回归方式,从左到右、从上到下逐步生成图像,这可能是其文本渲染和对象绑定能力更强的原因。
这个功能更新现在对OpenAI每月200美元的Pro计划订阅用户开放,然后扩展到免费和Plus层级用户,还有就是通过OpenAI API的开发者。
详细情况:https://openai.com/index/introducing-4o-image-generation/
-
下一篇: 最后一页
- OpenAI GPT-4o模型推出重大更新:为ChatGPT增加了图像生成和编辑功能
- OpenAI推出的GPT-4o图像生成有哪些功能特点?
- ScoreFlow:一种自动化多智能体工作流生成和优化方法
- PDF-Craft:一个扫描书籍PDF文件转Markdown/EPUB工具
- BrowserAgent:一款基于浏览器的AI自动化工具,无需编写代码即可创建AI工作流。
- MoshiVis:一款能听还能看,并用流畅的语音跟你讨论图像内容的视觉语音模型
- Qwen2.5-Omni:阿里巴巴发布的端到端全能多模态旗舰模型
- Bonito入门指南 - 无需GPT即可生成指令调优数据集的轻量级库
- Mureka O1:昆仑万维发布的全球首款音乐推理大模型
- playwright-mcp:能够使大语言模型直接操控浏览器完成复杂任务
-
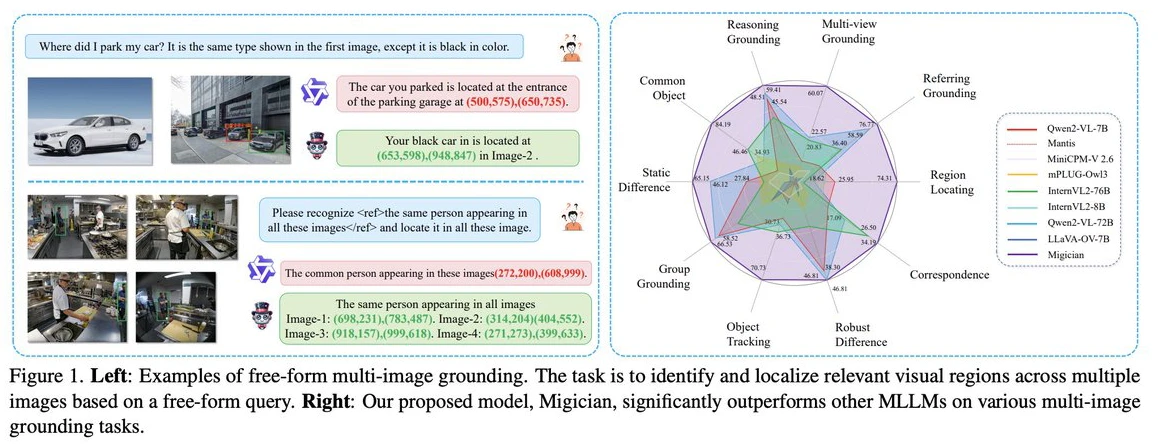
Migician:清华大学等团队出的解决复杂场景下的多图像目标定位问题的多模态模型
2025-03-11
-

MILS:Meta发布的无需训练就能让LLM获得多模态能力的方法
2025-03-28
-

2025-04-14
-
2025-02-24
-
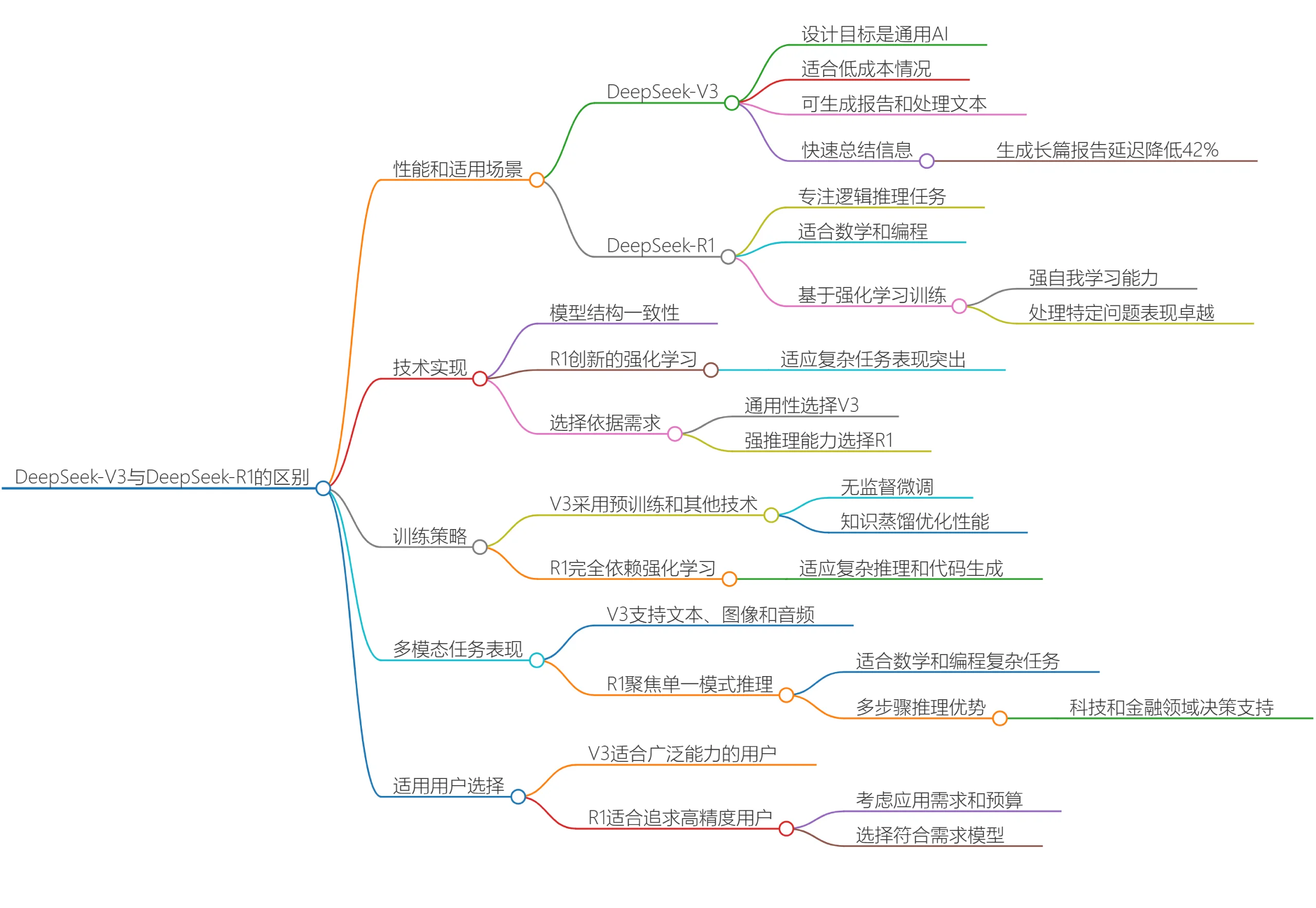
DeepSeek V3和DeepSeek R1有什么区别?哪个更适合你呢?
2025-03-20
-

2025-04-05
-

2025-04-21
-
文生图模型Ideogram 2A:更快的生成速度和更低的成本
2025-03-12
-
2025-03-28
-
HeyGem.ai:Heygen的开源平替产品,精确外貌与声音克隆,合成虚拟数字人视频
2025-04-15








